
PaddleNLP 一键预测功能:Taskflow API#



![]()

QuickStart | 社区交流 | 一键预测&定制训练 | FAQ
特性#
PaddleNLP 提供开箱即用的产业级 NLP 预置任务能力,无需训练,一键预测。
最全的中文任务:覆盖自然语言理解与自然语言生成两大核心应用;
极致的产业级效果:在多个中文场景上提供产业级的精度与预测性能;
统一的应用范式:通过
paddlenlp.Taskflow调用,简捷易用。
| 任务名称 | 调用方式 | 一键预测 | 单条输入 | 多条输入 | 文档级输入 | 定制化训练 | 其它特性 |
|---|---|---|---|---|---|---|---|
| 中文分词 | Taskflow("word_segmentation") |
✅ | ✅ | ✅ | ✅ | ✅ | 多种分词模式,满足快速切分和实体粒度精准切分 |
| 词性标注 | Taskflow("pos_tagging") |
✅ | ✅ | ✅ | ✅ | ✅ | 基于百度前沿词法分析工具 LAC |
| 命名实体识别 | Taskflow("ner") |
✅ | ✅ | ✅ | ✅ | ✅ | 覆盖最全中文实体标签 |
| 依存句法分析 | Taskflow("dependency_parsing") |
✅ | ✅ | ✅ | ✅ | 基于最大规模中文依存句法树库研发的 DDParser | |
| 信息抽取 | Taskflow("information_extraction") |
✅ | ✅ | ✅ | ✅ | ✅ | 适配多场景的开放域通用信息抽取工具 |
| 『解语』-知识标注 | Taskflow("knowledge_mining") |
✅ | ✅ | ✅ | ✅ | ✅ | 覆盖所有中文词汇的知识标注工具 |
| 文本纠错 | Taskflow("text_correction") |
✅ | ✅ | ✅ | ✅ | ✅ | 融合拼音特征的端到端文本纠错模型 ERNIE-CSC |
| 文本相似度 | Taskflow("text_similarity") |
✅ | ✅ | ✅ | 基于百万量级 Dureader Retrieval 数据集训练 RocketQA 并达到前沿文本相似效果 | ||
| 情感分析 | Taskflow("sentiment_analysis") |
✅ | ✅ | ✅ | ✅ | 集成 BiLSTM、SKEP、UIE 等模型,支持评论维度、观点抽取、情感极性分类等情感分析任务 | |
| 生成式问答 | Taskflow("question_answering") |
✅ | ✅ | ✅ | 使用最大中文开源 CPM 模型完成问答 | ||
| 智能写诗 | Taskflow("poetry_generation") |
✅ | ✅ | ✅ | 使用最大中文开源 CPM 模型完成写诗 | ||
| 开放域对话 | Taskflow("dialogue") |
✅ | ✅ | ✅ | 十亿级语料训练最强中文闲聊模型 PLATO-Mini,支持多轮对话 | ||
| 代码生成 | Taskflow("code_generation") |
✅ | ✅ | ✅ | ✅ | 代码生成大模型 | |
| 文本摘要 | Taskflow("text_summarization") |
✅ | ✅ | ✅ | ✅ | 文本摘要大模型 | |
| 文档智能 | Taskflow("document_intelligence") |
✅ | ✅ | ✅ | ✅ | 以多语言跨模态布局增强文档预训练模型 ERNIE-Layout 为核心底座 | |
| 问题生成 | Taskflow("question_generation") |
✅ | ✅ | ✅ | ✅ | 问题生成大模型 | |
| 零样本文本分类 | Taskflow("zero_shot_text_classification") |
✅ | ✅ | ✅ | ✅ | 集成多场景的通用文本分类工具 | |
| 模型特征提取 | Taskflow("feature_extraction") |
✅ | ✅ | ✅ | ✅ | 集成文本,图片的特征抽取工具 |
QuickStart#
环境依赖
python >= 3.6
paddlepaddle >= 2.3.0
paddlenlp >= 2.3.4
可进入 Jupyter Notebook 环境,在线体验 👉🏻 进入在线运行环境
PaddleNLP Taskflow API 支持任务持续丰富中,我们将根据开发者反馈,灵活调整功能建设优先级,可通过 Issue 或问卷反馈给我们。
社区交流👬#
微信扫描二维码并填写问卷之后,加入交流群领取福利
获取5月18-19日每晚20:30《产业级通用信息抽取技术 UIE+ERNIE 轻量级模型》直播课链接
10G 重磅 NLP 学习大礼包:

详细使用#
PART Ⅰ 一键预测#
中文分词#
(可展开详情)多种分词模式,满足快速切分和实体粒度精准切分
三种分词模式,满足各类分词需求#
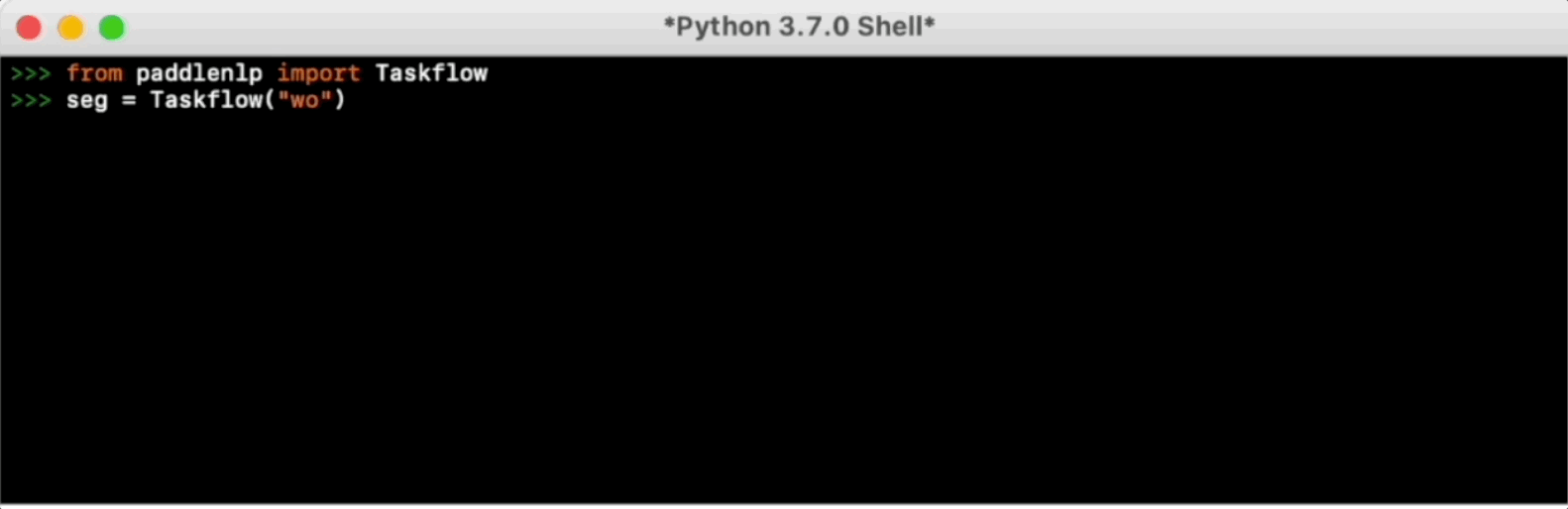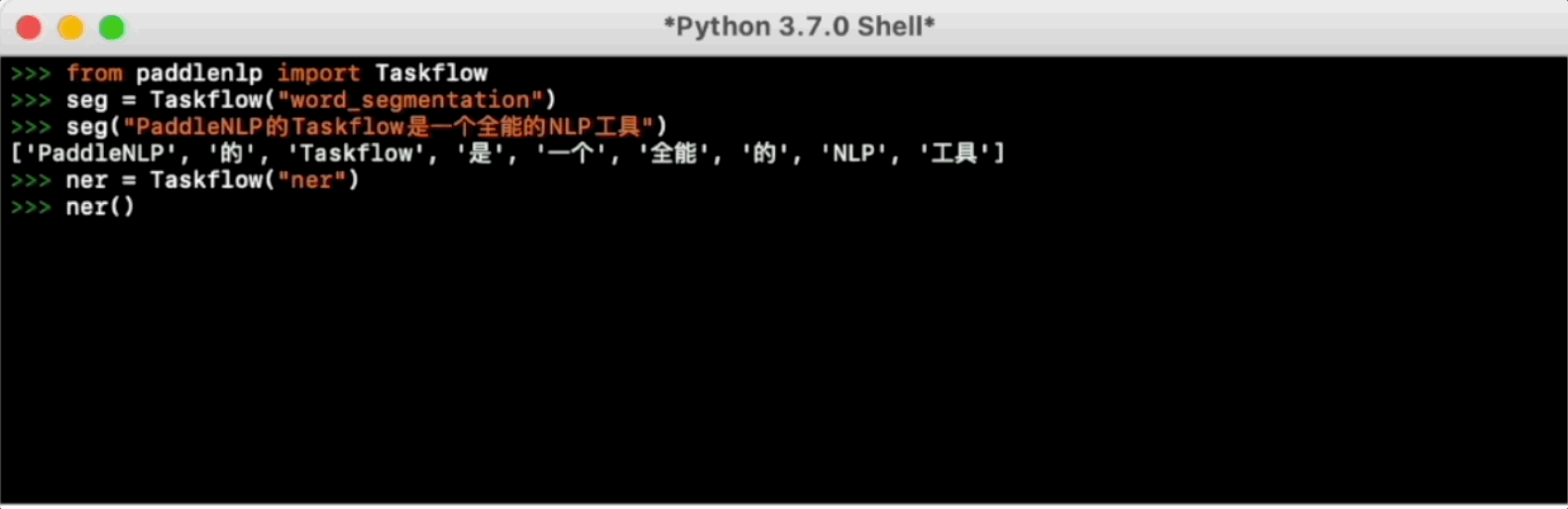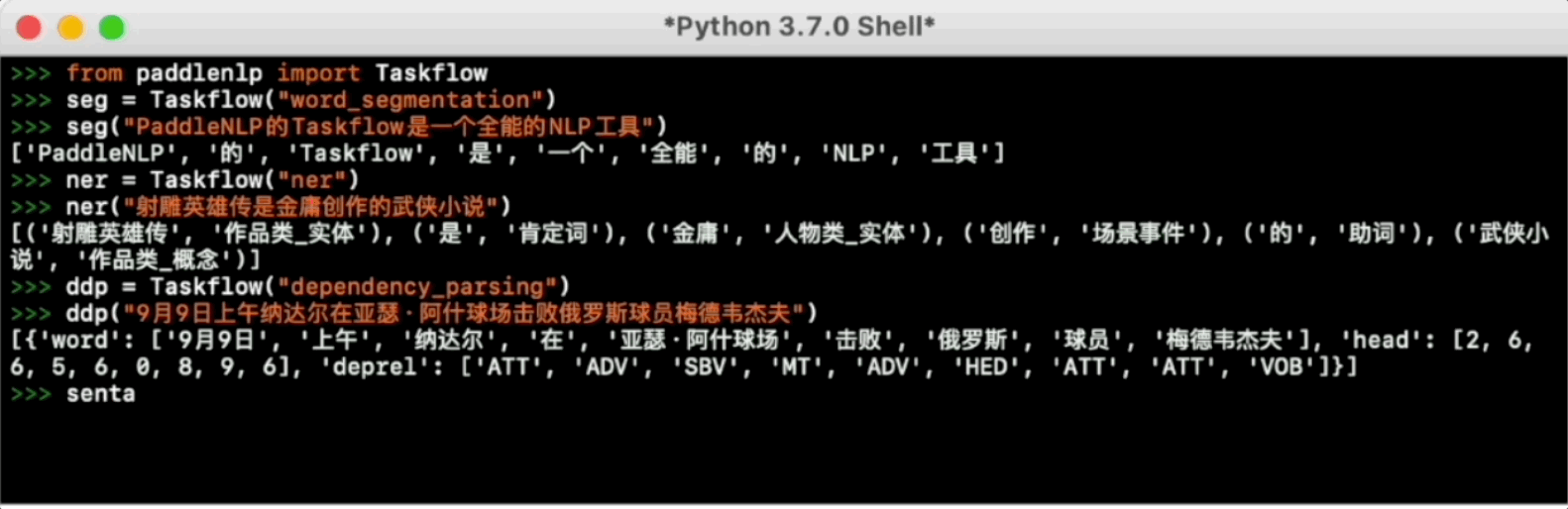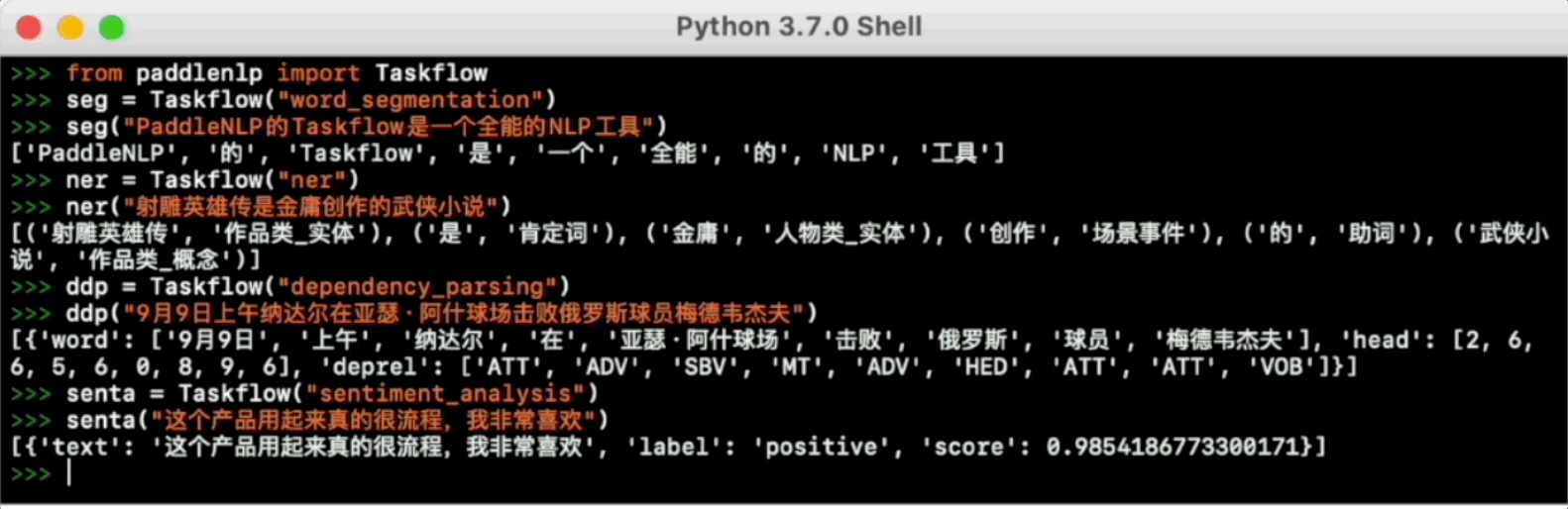
from paddlenlp import Taskflow
# 默认模式————实体粒度分词,在精度和速度上的权衡,基于百度LAC
>>> seg = Taskflow("word_segmentation")
>>> seg("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
['近日', '国家卫健委', '发布', '第九版', '新型', '冠状病毒肺炎', '诊疗', '方案']
# 快速模式————最快:实现文本快速切分,基于jieba中文分词工具
>>> seg_fast = Taskflow("word_segmentation", mode="fast")
>>> seg_fast("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
['近日', '国家', '卫健委', '发布', '第九版', '新型', '冠状病毒', '肺炎', '诊疗', '方案']
# 精确模式————最准:实体粒度切分准确度最高,基于百度解语
# 精确模式基于预训练模型,更适合实体粒度分词需求,适用于知识图谱构建、企业搜索Query分析等场景中
>>> seg_accurate = Taskflow("word_segmentation", mode="accurate")
>>> seg_accurate("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
['近日', '国家卫健委', '发布', '第九版', '新型冠状病毒肺炎', '诊疗', '方案']
批量样本输入,平均速度更快#
输入为多个句子组成的 list,平均速度会更快。
>>> from paddlenlp import Taskflow
>>> seg = Taskflow("word_segmentation")
>>> seg(["第十四届全运会在西安举办", "三亚是一个美丽的城市"])
[['第十四届', '全运会', '在', '西安', '举办'], ['三亚', '是', '一个', '美丽', '的', '城市']]
自定义词典#
你可以通过传入user_dict参数,装载自定义词典来定制分词结果。
在默认模式和精确模式下,词典文件每一行由一个或多个自定义 item 组成。词典文件user_dict.txt示例:
平原上的火焰
上 映
在快速模式下,词典文件每一行为一个自定义 item+"\t"+词频(词频可省略,词频省略则自动计算能保证分出该词的词频),暂时不支持黑名单词典(即通过设置”年“、”末“,以达到切分”年末“的目的)。词典文件user_dict.txt示例:
平原上的火焰 10
加载自定义词典及输出结果示例:
>>> from paddlenlp import Taskflow
>>> seg = Taskflow("word_segmentation")
>>> seg("平原上的火焰宣布延期上映")
['平原', '上', '的', '火焰', '宣布', '延期', '上映']
>>> seg = Taskflow("word_segmentation", user_dict="user_dict.txt")
>>> seg("平原上的火焰宣布延期上映")
['平原上的火焰', '宣布', '延期', '上', '映']
参数说明#
mode:指定分词模式,默认为 None。batch_size:批处理大小,请结合机器情况进行调整,默认为1。user_dict:自定义词典文件路径,默认为 None。task_path:自定义任务路径,默认为 None。
词性标注#
基于百度词法分析工具 LAC
支持单条和批量预测#
>>> from paddlenlp import Taskflow
# 单条预测
>>> tag = Taskflow("pos_tagging")
>>> tag("第十四届全运会在西安举办")
[('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')]
# 批量样本输入,平均速度更快
>>> tag(["第十四届全运会在西安举办", "三亚是一个美丽的城市"])
[[('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')], [('三亚', 'LOC'), ('是', 'v'), ('一个', 'm'), ('美丽', 'a'), ('的', 'u'), ('城市', 'n')]]
标签集合#
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
自定义词典#
你可以通过装载自定义词典来定制化分词和词性标注结果。词典文件每一行表示一个自定义 item,可以由一个单词或者多个单词组成,单词后面可以添加自定义标签,格式为item/tag,如果不添加自定义标签,则使用模型默认标签n。
词典文件user_dict.txt示例:
赛里木湖/LAKE
高/a 山/n
海拔最高
装载自定义词典及输出结果示例:
>>> from paddlenlp import Taskflow
>>> tag = Taskflow("pos_tagging")
>>> tag("赛里木湖是新疆海拔最高的高山湖泊")
[('赛里木湖', 'LOC'), ('是', 'v'), ('新疆', 'LOC'), ('海拔', 'n'), ('最高', 'a'), ('的', 'u'), ('高山', 'n'), ('湖泊', 'n')]
>>> my_tag = Taskflow("pos_tagging", user_dict="user_dict.txt")
>>> my_tag("赛里木湖是新疆海拔最高的高山湖泊")
[('赛里木湖', 'LAKE'), ('是', 'v'), ('新疆', 'LOC'), ('海拔最高', 'n'), ('的', 'u'), ('高', 'a'), ('山', 'n'), ('湖泊', 'n')]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。user_dict:用户自定义词典文件,默认为 None。task_path:自定义任务路径,默认为 None。
命名实体识别#
最全中文实体标签
支持两种模式#
# 精确模式(默认),基于百度解语,内置91种词性及专名类别标签
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner")
>>> ner("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
[('《', 'w'), ('孤女', '作品类_实体'), ('》', 'w'), ('是', '肯定词'), ('2010年', '时间类'), ('九州出版社', '组织机构类'), ('出版', '场景事件'), ('的', '助词'), ('小说', '作品类_概念'), (',', 'w'), ('作者', '人物类_概念'), ('是', '肯定词'), ('余兼羽', '人物类_实体')]
>>> ner = Taskflow("ner", entity_only=True) # 只返回实体/概念词
>>> ner("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
[('孤女', '作品类_实体'), ('2010年', '时间类'), ('九州出版社', '组织机构类'), ('出版', '场景事件'), ('小说', '作品类_概念'), ('作者', '人物类_概念'), ('余兼羽', '人物类_实体')]
# 快速模式,基于百度LAC,内置24种词性和专名类别标签
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner", mode="fast")
>>> ner("三亚是一个美丽的城市")
[('三亚', 'LOC'), ('是', 'v'), ('一个', 'm'), ('美丽', 'a'), ('的', 'u'), ('城市', 'n')]
批量样本输入,平均速度更快#
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner")
>>> ner(["热梅茶是一道以梅子为主要原料制作的茶饮", "《孤女》是2010年九州出版社出版的小说,作者是余兼羽"])
[[('热梅茶', '饮食类_饮品'), ('是', '肯定词'), ('一道', '数量词'), ('以', '介词'), ('梅子', '饮食类'), ('为', '肯定词'), ('主要原料', '物体类'), ('制作', '场景事件'), ('的', '助词'), ('茶饮', '饮食类_饮品')], [('《', 'w'), ('孤女', '作品类_实体'), ('》', 'w'), ('是', '肯定词'), ('2010年', '时间类'), ('九州出版社', '组织机构类'), ('出版', '场景事件'), ('的', '助词'), ('小说', '作品类_概念'), (',', 'w'), ('作者', '人物类_概念'), ('是', '肯定词'), ('余兼羽', '人物类_实体')]]
实体标签说明#
精确模式采用的标签集合
包含91种词性及专名类别标签,标签集合如下表:
| WordTag 标签集合 | ||||||
|---|---|---|---|---|---|---|
| 人物类_实体 | 组织机构类_军事组织机构_概念 | 文化类_制度政策协议 | 位置方位 | 术语类_医药学术语 | 信息资料_性别 | 否定词 |
| 人物类_概念 | 组织机构类_医疗卫生机构 | 文化类_姓氏与人名 | 世界地区类 | 术语类_生物体 | 链接地址 | 数量词 |
| 作品类_实体 | 组织机构类_医疗卫生机构_概念 | 生物类 | 世界地区类_国家 | 疾病损伤类 | 个性特征 | 数量词_序数词 |
| 作品类_概念 | 组织机构类_教育组织机构 | 生物类_植物 | 世界地区类_区划概念 | 疾病损伤类_植物病虫害 | 感官特征 | 数量词_单位数量词 |
| 组织机构类 | 组织机构类_教育组织机构_概念 | 生物类_动物 | 世界地区类_地理概念 | 宇宙类 | 场景事件 | 叹词 |
| 组织机构类_概念 | 物体类 | 品牌名 | 饮食类 | 事件类 | 介词 | 拟声词 |
| 组织机构类_企事业单位 | 物体类_概念 | 品牌名_品牌类型 | 饮食类_菜品 | 时间类 | 介词_方位介词 | 修饰词 |
| 组织机构类_企事业单位_概念 | 物体类_兵器 | 场所类 | 饮食类_饮品 | 时间类_特殊日 | 助词 | 修饰词_性质 |
| 组织机构类_国家机关 | 物体类_化学物质 | 场所类_概念 | 药物类 | 时间类_朝代 | 代词 | 修饰词_类型 |
| 组织机构类_国家机关_概念 | 其他角色类 | 场所类_交通场所 | 药物类_中药 | 时间类_具体时间 | 连词 | 修饰词_化 |
| 组织机构类_体育组织机构 | 文化类 | 场所类_交通场所_概念 | 术语类 | 时间类_时长 | 副词 | 外语单词 |
| 组织机构类_体育组织机构_概念 | 文化类_语言文字 | 场所类_网上场所 | 术语类_术语类型 | 词汇用语 | 疑问词 | 汉语拼音 |
| 组织机构类_军事组织机构 | 文化类_奖项赛事活动 | 场所类_网上场所_概念 | 术语类_符号指标类 | 信息资料 | 肯定词 | w(标点) |
快速模式采用的标签集合
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
自定义词典#
你可以通过装载自定义词典来定制化命名实体识别结果。词典文件每一行表示一个自定义 item,可以由一个 term 或者多个 term 组成,term 后面可以添加自定义标签,格式为item/tag,如果不添加自定义标签,则使用模型默认标签。
词典文件user_dict.txt示例:
长津湖/电影类_实体
收/词汇用语 尾/术语类
最 大
海外票仓
以"《长津湖》收尾,北美是最大海外票仓"为例,原本的输出结果为:
[('《', 'w'), ('长津湖', '作品类_实体'), ('》', 'w'), ('收尾', '场景事件'), (',', 'w'), ('北美', '世界地区类'), ('是', '肯定词'), ('最大', '修饰词'), ('海外', '场所类'), ('票仓', '词汇用语')]
装载自定义词典及输出结果示例:
>>> from paddlenlp import Taskflow
>>> my_ner = Taskflow("ner", user_dict="user_dict.txt")
>>> my_ner("《长津湖》收尾,北美是最大海外票仓")
[('《', 'w'), ('长津湖', '电影类_实体'), ('》', 'w'), ('收', '词汇用语'), ('尾', '术语类'), (',', 'w'), ('北美', '世界地区类'), ('是', '肯定词'), ('最', '修饰词'), ('大', '修饰词'), ('海外票仓', '场所类')]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。user_dict:用户自定义词典文件,默认为 None。task_path:自定义任务路径,默认为 None。entity_only:只返回实体/概念词及其对应标签。
依存句法分析#
基于最大规模中文依存句法树库研发的 DDParser
支持多种形式输入#
未分词输入:
>>> from paddlenlp import Taskflow
>>> ddp = Taskflow("dependency_parsing")
>>> ddp("2月8日谷爱凌夺得北京冬奥会第三金")
[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}]
使用分词结果来输入:
>>> ddp = Taskflow("dependency_parsing")
>>> ddp.from_segments([['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金']])
[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}]
批量样本输入,平均速度更快#
>>> from paddlenlp import Taskflow
>>> ddp(["2月8日谷爱凌夺得北京冬奥会第三金", "他送了一本书"])
[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}, {'word': ['他', '送', '了', '一本', '书'], 'head': [2, 0, 2, 5, 2], 'deprel': ['SBV', 'HED', 'MT', 'ATT', 'VOB']}]
多种模型选择,满足精度、速度需求#
使用 ERNIE 1.0进行预测
>>> ddp = Taskflow("dependency_parsing", model="ddparser-ernie-1.0")
>>> ddp("2月8日谷爱凌夺得北京冬奥会第三金")
[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}]
除 ERNIE 1.0外,还可使用 ERNIE-Gram 预训练模型,其中model=ddparser(基于 LSTM Encoder)速度最快,model=ddparser-ernie-gram-zh和model=ddparser-ernie-1.0效果更优(两者效果相当)。
输出方式#
输出概率值和词性标签:
>>> ddp = Taskflow("dependency_parsing", prob=True, use_pos=True)
>>> ddp("2月8日谷爱凌夺得北京冬奥会第三金")
[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB'], 'postag': ['TIME', 'PER', 'v', 'ORG', 'n'], 'prob': [0.97, 1.0, 1.0, 0.99, 0.99]}]
依存关系可视化
>>> from paddlenlp import Taskflow
>>> ddp = Taskflow("dependency_parsing", return_visual=True)
>>> result = ddp("2月8日谷爱凌夺得北京冬奥会第三金")[0]['visual']
>>> import cv2
>>> cv2.imwrite('test.png', result)

依存句法分析标注关系集合#
| Label | 关系类型 | 说明 | 示例 |
|---|---|---|---|
| SBV | 主谓关系 | 主语与谓词间的关系 | 他送了一本书(他<--送) |
| VOB | 动宾关系 | 宾语与谓词间的关系 | 他送了一本书(送-->书) |
| POB | 介宾关系 | 介词与宾语间的关系 | 我把书卖了(把-->书) |
| ADV | 状中关系 | 状语与中心词间的关系 | 我昨天买书了(昨天<--买) |
| CMP | 动补关系 | 补语与中心词间的关系 | 我都吃完了(吃-->完) |
| ATT | 定中关系 | 定语与中心词间的关系 | 他送了一本书(一本<--书) |
| F | 方位关系 | 方位词与中心词的关系 | 在公园里玩耍(公园-->里) |
| COO | 并列关系 | 同类型词语间关系 | 叔叔阿姨(叔叔-->阿姨) |
| DBL | 兼语结构 | 主谓短语做宾语的结构 | 他请我吃饭(请-->我,请-->吃饭) |
| DOB | 双宾语结构 | 谓语后出现两个宾语 | 他送我一本书(送-->我,送-->书) |
| VV | 连谓结构 | 同主语的多个谓词间关系 | 他外出吃饭(外出-->吃饭) |
| IC | 子句结构 | 两个结构独立或关联的单句 | 你好,书店怎么走?(你好<--走) |
| MT | 虚词成分 | 虚词与中心词间的关系 | 他送了一本书(送-->了) |
| HED | 核心关系 | 指整个句子的核心 |
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。model:选择任务使用的模型,可选有ddparser,ddparser-ernie-1.0和ddparser-ernie-gram-zh。tree:确保输出结果是正确的依存句法树,默认为 True。prob:是否输出每个弧对应的概率值,默认为 False。use_pos:是否返回词性标签,默认为 False。use_cuda:是否使用 GPU 进行切词,默认为 False。return_visual:是否返回句法树的可视化结果,默认为 False。task_path:自定义任务路径,默认为 None。
信息抽取#
适配多场景的开放域通用信息抽取工具
开放域信息抽取是信息抽取的一种全新范式,主要思想是减少人工参与,利用单一模型支持多种类型的开放抽取任务,用户可以使用自然语言自定义抽取目标,在实体、关系类别等未定义的情况下抽取输入文本中的信息片段。
实体抽取#
命名实体识别(Named Entity Recognition,简称 NER),是指识别文本中具有特定意义的实体。在开放域信息抽取中,抽取的类别没有限制,用户可以自己定义。
例如抽取的目标实体类型是"时间"、"选手"和"赛事名称", schema 构造如下:
['时间', '选手', '赛事名称']
调用示例:
>>> from pprint import pprint >>> from paddlenlp import Taskflow >>> schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction >>> ie = Taskflow('information_extraction', schema=schema) >>> pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint [{'时间': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}], '赛事名称': [{'end': 23, 'probability': 0.8503089953268272, 'start': 6, 'text': '北京冬奥会自由式滑雪女子大跳台决赛'}], '选手': [{'end': 31, 'probability': 0.8981548639781138, 'start': 28, 'text': '谷爱凌'}]}]
例如抽取的目标实体类型是"肿瘤的大小"、"肿瘤的个数"、"肝癌级别"和"脉管内癌栓分级", schema 构造如下:
['肿瘤的大小', '肿瘤的个数', '肝癌级别', '脉管内癌栓分级']
在上例中我们已经实例化了一个
Taskflow对象,这里可以通过set_schema方法重置抽取目标。调用示例:
>>> schema = ['肿瘤的大小', '肿瘤的个数', '肝癌级别', '脉管内癌栓分级'] >>> ie.set_schema(schema) >>> pprint(ie("(右肝肿瘤)肝细胞性肝癌(II-III级,梁索型和假腺管型),肿瘤包膜不完整,紧邻肝被膜,侵及周围肝组织,未见脉管内癌栓(MVI分级:M0级)及卫星子灶形成。(肿物1个,大小4.2×4.0×2.8cm)。")) [{'肝癌级别': [{'end': 20, 'probability': 0.9243267447402701, 'start': 13, 'text': 'II-III级'}], '肿瘤的个数': [{'end': 84, 'probability': 0.7538413804059623, 'start': 82, 'text': '1个'}], '肿瘤的大小': [{'end': 100, 'probability': 0.8341128043459491, 'start': 87, 'text': '4.2×4.0×2.8cm'}], '脉管内癌栓分级': [{'end': 70, 'probability': 0.9083292325934664, 'start': 67, 'text': 'M0级'}]}]
例如抽取的目标实体类型是"person"和"organization",schema 构造如下:
['person', 'organization']
英文模型调用示例:
>>> from pprint import pprint >>> from paddlenlp import Taskflow >>> schema = ['Person', 'Organization'] >>> ie_en = Taskflow('information_extraction', schema=schema, model='uie-base-en') >>> pprint(ie_en('In 1997, Steve was excited to become the CEO of Apple.')) [{'Organization': [{'end': 53, 'probability': 0.9985840259877357, 'start': 48, 'text': 'Apple'}], 'Person': [{'end': 14, 'probability': 0.999631971804547, 'start': 9, 'text': 'Steve'}]}]
关系抽取#
关系抽取(Relation Extraction,简称 RE),是指从文本中识别实体并抽取实体之间的语义关系,进而获取三元组信息,即<主体,谓语,客体>。
例如以"竞赛名称"作为抽取主体,抽取关系类型为"主办方"、"承办方"和"已举办次数", schema 构造如下:
{ '竞赛名称': [ '主办方', '承办方', '已举办次数' ] }调用示例:
>>> schema = {'竞赛名称': ['主办方', '承办方', '已举办次数']} # Define the schema for relation extraction >>> ie.set_schema(schema) # Reset schema >>> pprint(ie('2022语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,已连续举办4届,成为全球最热门的中文NLP赛事之一。')) [{'竞赛名称': [{'end': 13, 'probability': 0.7825402622754041, 'relations': {'主办方': [{'end': 22, 'probability': 0.8421710521379353, 'start': 14, 'text': '中国中文信息学会'}, {'end': 30, 'probability': 0.7580801847701935, 'start': 23, 'text': '中国计算机学会'}], '已举办次数': [{'end': 82, 'probability': 0.4671295049136148, 'start': 80, 'text': '4届'}], '承办方': [{'end': 39, 'probability': 0.8292706618236352, 'start': 35, 'text': '百度公司'}, {'end': 72, 'probability': 0.6193477885474685, 'start': 56, 'text': '中国计算机学会自然语言处理专委会'}, {'end': 55, 'probability': 0.7000497331473241, 'start': 40, 'text': '中国中文信息学会评测工作委员会'}]}, 'start': 0, 'text': '2022语言与智能技术竞赛'}]}]
例如以"person"作为抽取主体,抽取关系类型为"Company"和"Position", schema 构造如下:
{ 'Person': [ 'Company', 'Position' ] }英文模型调用示例:
>>> schema = [{'Person': ['Company', 'Position']}] >>> ie_en.set_schema(schema) >>> pprint(ie_en('In 1997, Steve was excited to become the CEO of Apple.')) [{'Person': [{'end': 14, 'probability': 0.999631971804547, 'relations': {'Company': [{'end': 53, 'probability': 0.9960158209451642, 'start': 48, 'text': 'Apple'}], 'Position': [{'end': 44, 'probability': 0.8871063806420736, 'start': 41, 'text': 'CEO'}]}, 'start': 9, 'text': 'Steve'}]}]
事件抽取#
事件抽取 (Event Extraction, 简称 EE),是指从自然语言文本中抽取预定义的事件触发词(Trigger)和事件论元(Argument),组合为相应的事件结构化信息。
例如抽取的目标是"地震"事件的"地震强度"、"时间"、"震中位置"和"震源深度"这些信息,schema 构造如下:
{ '地震触发词': [ '地震强度', '时间', '震中位置', '震源深度' ] }触发词的格式统一为
触发词或``XX 触发词,XX表示具体事件类型,上例中的事件类型是地震,则对应触发词为地震触发词`。调用示例:
>>> schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # Define the schema for event extraction >>> ie.set_schema(schema) # Reset schema >>> ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。') [{'地震触发词': [{'text': '地震', 'start': 56, 'end': 58, 'probability': 0.9987181623528585, 'relations': {'地震强度': [{'text': '3.5级', 'start': 52, 'end': 56, 'probability': 0.9962985320905915}], '时间': [{'text': '5月16日06时08分', 'start': 11, 'end': 22, 'probability': 0.9882578028575182}], '震中位置': [{'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)', 'start': 23, 'end': 50, 'probability': 0.8551415716584501}], '震源深度': [{'text': '10千米', 'start': 63, 'end': 67, 'probability': 0.999158304648045}]}}]}]
英文模型 zero-shot 方式暂不支持事件抽取,如有英文事件抽取相关语料请进行训练定制。
评论观点抽取#
评论观点抽取,是指抽取文本中包含的评价维度、观点词。
例如抽取的目标是文本中包含的评价维度及其对应的观点词和情感倾向,schema 构造如下:
{ '评价维度': [ '观点词', '情感倾向[正向,负向]' ] }调用示例:
>>> schema = {'评价维度': ['观点词', '情感倾向[正向,负向]']} # Define the schema for opinion extraction >>> ie.set_schema(schema) # Reset schema >>> pprint(ie("店面干净,很清静,服务员服务热情,性价比很高,发现收银台有排队")) # Better print results using pprint [{'评价维度': [{'end': 20, 'probability': 0.9817040258681473, 'relations': {'情感倾向[正向,负向]': [{'probability': 0.9966142505350533, 'text': '正向'}], '观点词': [{'end': 22, 'probability': 0.957396472711558, 'start': 21, 'text': '高'}]}, 'start': 17, 'text': '性价比'}, {'end': 2, 'probability': 0.9696849569741168, 'relations': {'情感倾向[正向,负向]': [{'probability': 0.9982153274927796, 'text': '正向'}], '观点词': [{'end': 4, 'probability': 0.9945318044652538, 'start': 2, 'text': '干净'}]}, 'start': 0, 'text': '店面'}]}]
英文模型 schema 构造如下:
{ 'Aspect': [ 'Opinion', 'Sentiment classification [negative, positive]' ] }英文模型调用示例:
>>> schema = [{'Aspect': ['Opinion', 'Sentiment classification [negative, positive]']}] >>> ie_en.set_schema(schema) >>> pprint(ie_en("The teacher is very nice.")) [{'Aspect': [{'end': 11, 'probability': 0.4301476415932193, 'relations': {'Opinion': [{'end': 24, 'probability': 0.9072940447883724, 'start': 15, 'text': 'very nice'}], 'Sentiment classification [negative, positive]': [{'probability': 0.9998571920670685, 'text': 'positive'}]}, 'start': 4, 'text': 'teacher'}]}]
情感分类#
句子级情感倾向分类,即判断句子的情感倾向是“正向”还是“负向”,schema 构造如下:
'情感倾向[正向,负向]'
调用示例:
>>> schema = '情感倾向[正向,负向]' # Define the schema for sentence-level sentiment classification >>> ie.set_schema(schema) # Reset schema >>> ie('这个产品用起来真的很流畅,我非常喜欢') [{'情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.9988661643929895}]}]
英文模型 schema 构造如下:
'情感倾向[正向,负向]'
英文模型调用示例:
>>> schema = 'Sentiment classification [negative, positive]' >>> ie_en.set_schema(schema) >>> ie_en('I am sorry but this is the worst film I have ever seen in my life.') [{'Sentiment classification [negative, positive]': [{'text': 'negative', 'probability': 0.9998415771287057}]}]
跨任务抽取#
例如在法律场景同时对文本进行实体抽取和关系抽取,schema 可按照如下方式进行构造:
[ "法院", { "原告": "委托代理人" }, { "被告": "委托代理人" } ]调用示例:
>>> schema = ['法院', {'原告': '委托代理人'}, {'被告': '委托代理人'}] >>> ie.set_schema(schema) >>> pprint(ie("北京市海淀区人民法院\n民事判决书\n(199x)建初字第xxx号\n原告:张三。\n委托代理人李四,北京市 A律师事务所律师。\n被告:B公司,法定代表人王五,开发公司总经理。\n委托代理人赵六,北京市 C律师事务所律师。")) # Better print results using pprint [{'原告': [{'end': 37, 'probability': 0.9949814024296764, 'relations': {'委托代理人': [{'end': 46, 'probability': 0.7956844697990384, 'start': 44, 'text': '李四'}]}, 'start': 35, 'text': '张三'}], '法院': [{'end': 10, 'probability': 0.9221074192336651, 'start': 0, 'text': '北京市海淀区人民法院'}], '被告': [{'end': 67, 'probability': 0.8437349536631089, 'relations': {'委托代理人': [{'end': 92, 'probability': 0.7267121388225029, 'start': 90, 'text': '赵六'}]}, 'start': 64, 'text': 'B公司'}]}]
模型选择#
多模型选择,满足精度、速度要求
| 模型 | 结构 | 语言 |
|---|---|---|
uie-base (默认) |
12-layers, 768-hidden, 12-heads | 中文 |
uie-base-en |
12-layers, 768-hidden, 12-heads | 英文 |
uie-medical-base |
12-layers, 768-hidden, 12-heads | 中文 |
uie-medium |
6-layers, 768-hidden, 12-heads | 中文 |
uie-mini |
6-layers, 384-hidden, 12-heads | 中文 |
uie-micro |
4-layers, 384-hidden, 12-heads | 中文 |
uie-nano |
4-layers, 312-hidden, 12-heads | 中文 |
uie-m-large |
24-layers, 1024-hidden, 16-heads | 中、英文 |
uie-m-base |
12-layers, 768-hidden, 12-heads | 中、英文 |
uie-nano调用示例:>>> from paddlenlp import Taskflow >>> schema = ['时间', '选手', '赛事名称'] >>> ie = Taskflow('information_extraction', schema=schema, model="uie-nano") >>> ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!") [{'时间': [{'text': '2月8日上午', 'start': 0, 'end': 6, 'probability': 0.6513581678349247}], '选手': [{'text': '谷爱凌', 'start': 28, 'end': 31, 'probability': 0.9819330659468051}], '赛事名称': [{'text': '北京冬奥会自由式滑雪女子大跳台决赛', 'start': 6, 'end': 23, 'probability': 0.4908131110420939}]}]
uie-m-base和uie-m-large支持中英文混合抽取,调用示例:>>> from pprint import pprint >>> from paddlenlp import Taskflow >>> schema = ['Time', 'Player', 'Competition', 'Score'] >>> ie = Taskflow('information_extraction', schema=schema, model="uie-m-base", schema_lang="en") >>> pprint(ie(["2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!", "Rafael Nadal wins French Open Final!"])) [{'Competition': [{'end': 23, 'probability': 0.9373889907291257, 'start': 6, 'text': '北京冬奥会自由式滑雪女子大跳台决赛'}], 'Player': [{'end': 31, 'probability': 0.6981119555336441, 'start': 28, 'text': '谷爱凌'}], 'Score': [{'end': 39, 'probability': 0.9888507878270296, 'start': 32, 'text': '188.25分'}], 'Time': [{'end': 6, 'probability': 0.9784080036931151, 'start': 0, 'text': '2月8日上午'}]}, {'Competition': [{'end': 35, 'probability': 0.9851549932171295, 'start': 18, 'text': 'French Open Final'}], 'Player': [{'end': 12, 'probability': 0.9379371275888104, 'start': 0, 'text': 'Rafael Nadal'}]}]
定制训练#
对于简单的抽取目标可以直接使用 paddlenlp.Taskflow实现零样本(zero-shot)抽取,对于细分场景我们推荐使用定制训练(标注少量数据进行模型微调)以进一步提升效果。
我们在互联网、医疗、金融三大垂类自建测试集上进行了实验:
| 金融 | 医疗 | 互联网 | ||||
|---|---|---|---|---|---|---|
| 0-shot | 5-shot | 0-shot | 5-shot | 0-shot | 5-shot | |
| uie-base (12L768H) | 46.43 | 70.92 | 71.83 | 85.72 | 78.33 | 81.86 |
| uie-medium (6L768H) | 41.11 | 64.53 | 65.40 | 75.72 | 78.32 | 79.68 |
| uie-mini (6L384H) | 37.04 | 64.65 | 60.50 | 78.36 | 72.09 | 76.38 |
| uie-micro (4L384H) | 37.53 | 62.11 | 57.04 | 75.92 | 66.00 | 70.22 |
| uie-nano (4L312H) | 38.94 | 66.83 | 48.29 | 76.74 | 62.86 | 72.35 |
| uie-m-large (24L1024H) | 49.35 | 74.55 | 70.50 | 92.66 | 78.49 | 83.02 |
| uie-m-base (12L768H) | 38.46 | 74.31 | 63.37 | 87.32 | 76.27 | 80.13 |
0-shot 表示无训练数据直接通过 paddlenlp.Taskflow进行预测,5-shot 表示每个类别包含5条标注数据进行模型微调。实验表明 UIE 在垂类场景可以通过少量数据(few-shot)进一步提升效果。
可配置参数说明#
schema:定义任务抽取目标,可参考开箱即用中不同任务的调用示例进行配置。schema_lang:设置 schema 的语言,默认为zh, 可选有zh和en。因为中英 schema 的构造有所不同,因此需要指定 schema 的语言。该参数只对uie-m-base和uie-m-large模型有效。batch_size:批处理大小,请结合机器情况进行调整,默认为1。model:选择任务使用的模型,默认为uie-base,可选有uie-base,uie-medium,uie-mini,uie-micro,uie-nano,uie-medical-base,uie-base-en。position_prob:模型对于 span 的起始位置/终止位置的结果概率0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5,span 的最终概率输出为起始位置概率和终止位置概率的乘积。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装 NVIDIA 相关驱动和基础软件,确保 CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖(主要是确保安装 onnxruntime-gpu)。其次,需要确保 GPU 设备的 CUDA 计算能力(CUDA Compute Capability)大于7.0,典型的设备包括 V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于 CUDA Compute Capability 和精度支持情况请参考 NVIDIA 文档:GPU 硬件与支持精度对照表。
解语知识标注#
覆盖所有中文词汇的知识标注工具
词类知识标注#
>>> from paddlenlp import Taskflow
>>> wordtag = Taskflow("knowledge_mining")
>>> wordtag("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
[{'text': '《孤女》是2010年九州出版社出版的小说,作者是余兼羽', 'items': [{'item': '《', 'offset': 0, 'wordtag_label': 'w', 'length': 1}, {'item': '孤女', 'offset': 1, 'wordtag_label': '作品类_实体', 'length': 2}, {'item': '》', 'offset': 3, 'wordtag_label': 'w', 'length': 1}, {'item': '是', 'offset': 4, 'wordtag_label': '肯定词', 'length': 1, 'termid': '肯定否定词_cb_是'}, {'item': '2010年', 'offset': 5, 'wordtag_label': '时间类', 'length': 5, 'termid': '时间阶段_cb_2010年'}, {'item': '九州出版社', 'offset': 10, 'wordtag_label': '组织机构类', 'length': 5, 'termid': '组织机构_eb_九州出版社'}, {'item': '出版', 'offset': 15, 'wordtag_label': '场景事件', 'length': 2, 'termid': '场景事件_cb_出版'}, {'item': '的', 'offset': 17, 'wordtag_label': '助词', 'length': 1, 'termid': '助词_cb_的'}, {'item': '小说', 'offset': 18, 'wordtag_label': '作品类_概念', 'length': 2, 'termid': '小说_cb_小说'}, {'item': ',', 'offset': 20, 'wordtag_label': 'w', 'length': 1}, {'item': '作者', 'offset': 21, 'wordtag_label': '人物类_概念', 'length': 2, 'termid': '人物_cb_作者'}, {'item': '是', 'offset': 23, 'wordtag_label': '肯定词', 'length': 1, 'termid': '肯定否定词_cb_是'}, {'item': '余兼羽', 'offset': 24, 'wordtag_label': '人物类_实体', 'length': 3}]}]
可配置参数说明:
batch_size:批处理大小,请结合机器情况进行调整,默认为1。linking:实现基于词类的 linking,默认为 True。task_path:自定义任务路径,默认为 None。user_dict:用户自定义词典文件,默认为 None。
知识挖掘-词类知识标注任务共包含91种词性及专名类别标签,标签集合如下表:
| WordTag 标签集合 | ||||||
|---|---|---|---|---|---|---|
| 人物类_实体 | 组织机构类_军事组织机构_概念 | 文化类_制度政策协议 | 位置方位 | 术语类_医药学术语 | 信息资料_性别 | 否定词 |
| 人物类_概念 | 组织机构类_医疗卫生机构 | 文化类_姓氏与人名 | 世界地区类 | 术语类_生物体 | 链接地址 | 数量词 |
| 作品类_实体 | 组织机构类_医疗卫生机构_概念 | 生物类 | 世界地区类_国家 | 疾病损伤类 | 个性特征 | 数量词_序数词 |
| 作品类_概念 | 组织机构类_教育组织机构 | 生物类_植物 | 世界地区类_区划概念 | 疾病损伤类_植物病虫害 | 感官特征 | 数量词_单位数量词 |
| 组织机构类 | 组织机构类_教育组织机构_概念 | 生物类_动物 | 世界地区类_地理概念 | 宇宙类 | 场景事件 | 叹词 |
| 组织机构类_概念 | 物体类 | 品牌名 | 饮食类 | 事件类 | 介词 | 拟声词 |
| 组织机构类_企事业单位 | 物体类_概念 | 品牌名_品牌类型 | 饮食类_菜品 | 时间类 | 介词_方位介词 | 修饰词 |
| 组织机构类_企事业单位_概念 | 物体类_兵器 | 场所类 | 饮食类_饮品 | 时间类_特殊日 | 助词 | 修饰词_性质 |
| 组织机构类_国家机关 | 物体类_化学物质 | 场所类_概念 | 药物类 | 时间类_朝代 | 代词 | 修饰词_类型 |
| 组织机构类_国家机关_概念 | 其他角色类 | 场所类_交通场所 | 药物类_中药 | 时间类_具体时间 | 连词 | 修饰词_化 |
| 组织机构类_体育组织机构 | 文化类 | 场所类_交通场所_概念 | 术语类 | 时间类_时长 | 副词 | 外语单词 |
| 组织机构类_体育组织机构_概念 | 文化类_语言文字 | 场所类_网上场所 | 术语类_术语类型 | 词汇用语 | 疑问词 | 汉语拼音 |
| 组织机构类_军事组织机构 | 文化类_奖项赛事活动 | 场所类_网上场所_概念 | 术语类_符号指标类 | 信息资料 | 肯定词 | w(标点) |
知识模板信息抽取#
>>> from paddlenlp import Taskflow
>>> wordtag_ie = Taskflow("knowledge_mining", with_ie=True)
>>> wordtag_ie('《忘了所有》是一首由王杰作词、作曲并演唱的歌曲,收录在专辑同名《忘了所有》中,由波丽佳音唱片于1996年08月31日发行。')
[[{'text': '《忘了所有》是一首由王杰作词、作曲并演唱的歌曲,收录在专辑同名《忘了所有》中,由波丽佳音唱片于1996年08月31日发行。', 'items': [{'item': '《', 'offset': 0, 'wordtag_label': 'w', 'length': 1}, {'item': '忘了所有', 'offset': 1, 'wordtag_label': '作品类_实体', 'length': 4}, {'item': '》', 'offset': 5, 'wordtag_label': 'w', 'length': 1}, {'item': '是', 'offset': 6, 'wordtag_label': '肯定词', 'length': 1}, {'item': '一首', 'offset': 7, 'wordtag_label': '数量词_单位数量词', 'length': 2}, {'item': '由', 'offset': 9, 'wordtag_label': '介词', 'length': 1}, {'item': '王杰', 'offset': 10, 'wordtag_label': '人物类_实体', 'length': 2}, {'item': '作词', 'offset': 12, 'wordtag_label': '场景事件', 'length': 2}, {'item': '、', 'offset': 14, 'wordtag_label': 'w', 'length': 1}, {'item': '作曲', 'offset': 15, 'wordtag_label': '场景事件', 'length': 2}, {'item': '并', 'offset': 17, 'wordtag_label': '连词', 'length': 1}, {'item': '演唱', 'offset': 18, 'wordtag_label': '场景事件', 'length': 2}, {'item': '的', 'offset': 20, 'wordtag_label': '助词', 'length': 1}, {'item': '歌曲', 'offset': 21, 'wordtag_label': '作品类_概念', 'length': 2}, {'item': ',', 'offset': 23, 'wordtag_label': 'w', 'length': 1}, {'item': '收录', 'offset': 24, 'wordtag_label': '场景事件', 'length': 2}, {'item': '在', 'offset': 26, 'wordtag_label': '介词', 'length': 1}, {'item': '专辑', 'offset': 27, 'wordtag_label': '作品类_概念', 'length': 2}, {'item': '同名', 'offset': 29, 'wordtag_label': '场景事件', 'length': 2}, {'item': '《', 'offset': 31, 'wordtag_label': 'w', 'length': 1}, {'item': '忘了所有', 'offset': 32, 'wordtag_label': '作品类_实体', 'length': 4}, {'item': '》', 'offset': 36, 'wordtag_label': 'w', 'length': 1}, {'item': '中', 'offset': 37, 'wordtag_label': '词汇用语', 'length': 1}, {'item': ',', 'offset': 38, 'wordtag_label': 'w', 'length': 1}, {'item': '由', 'offset': 39, 'wordtag_label': '介词', 'length': 1}, {'item': '波丽佳音', 'offset': 40, 'wordtag_label': '人物类_实体', 'length': 4}, {'item': '唱片', 'offset': 44, 'wordtag_label': '作品类_概念', 'length': 2}, {'item': '于', 'offset': 46, 'wordtag_label': '介词', 'length': 1}, {'item': '1996年08月31日', 'offset': 47, 'wordtag_label': '时间类_具体时间', 'length': 11}, {'item': '发行', 'offset': 58, 'wordtag_label': '场景事件', 'length': 2}, {'item': '。', 'offset': 60, 'wordtag_label': 'w', 'length': 1}]}], [[{'HEAD_ROLE': {'item': '王杰', 'offset': 10, 'type': '人物类_实体'}, 'TAIL_ROLE': [{'item': '忘了所有', 'type': '作品类_实体', 'offset': 1}], 'GROUP': '创作', 'TRIG': [{'item': '作词', 'offset': 12}, {'item': '作曲', 'offset': 15}, {'item': '演唱', 'offset': 18}], 'SRC': 'REVERSE'}, {'HEAD_ROLE': {'item': '忘了所有', 'type': '作品类_实体', 'offset': 1}, 'TAIL_ROLE': [{'item': '王杰', 'offset': 10, 'type': '人物类_实体'}], 'GROUP': '创作者', 'SRC': 'HTG', 'TRIG': [{'item': '作词', 'offset': 12}, {'item': '作曲', 'offset': 15}, {'item': '演唱', 'offset': 18}]}, {'HEAD_ROLE': {'item': '忘了所有', 'type': '作品类_实体', 'offset': 1}, 'TAIL_ROLE': [{'item': '歌曲', 'offset': 21, 'type': '作品类_概念'}], 'GROUP': '类型', 'SRC': 'TAIL'}, {'HEAD_ROLE': {'item': '忘了所有', 'offset': 32, 'type': '作品类_实体'}, 'TAIL_ROLE': [{'item': '忘了所有', 'type': '作品类_实体', 'offset': 1}], 'GROUP': '收录', 'TRIG': [{'item': '收录', 'offset': 24}], 'SRC': 'REVERSE'}, {'HEAD_ROLE': {'item': '忘了所有', 'type': '作品类_实体', 'offset': 1}, 'TAIL_ROLE': [{'item': '忘了所有', 'offset': 32, 'type': '作品类_实体'}], 'GROUP': '收录于', 'SRC': 'HGT', 'TRIG': [{'item': '收录', 'offset': 24}]}, {'HEAD_ROLE': {'item': '忘了所有', 'offset': 32, 'type': '作品类_实体'}, 'TAIL_ROLE': [{'item': '王杰', 'type': '人物类_实体', 'offset': 10}], 'GROUP': '创作者', 'TRIG': [{'item': '专辑', 'offset': 27}], 'SRC': 'REVERSE'}, {'HEAD_ROLE': {'item': '王杰', 'type': '人物类_实体', 'offset': 10}, 'TAIL_ROLE': [{'item': '忘了所有', 'offset': 32, 'type': '作品类_实体'}], 'GROUP': '创作', 'SRC': 'HGT', 'TRIG': [{'item': '专辑', 'offset': 27}]}, {'HEAD_ROLE': {'item': '忘了所有', 'type': '作品类_实体', 'offset': 32}, 'TAIL_ROLE': [{'item': '唱片', 'offset': 44, 'type': '作品类_概念'}], 'GROUP': '类型', 'SRC': 'TAIL'}]]]
自定义抽取的 schema
>>> from pprint import pprint
>>> schema = [
{
"head_role": "作品类_实体", #头实体词类
"group": "创作者", #关系名
"tail_role": [
{
"main": [
"人物类_实体" #尾实体词类
],
"support": [] #相关词类,可作为该关系的补充,不可作为尾实体独立存在
}
],
"trig_word": [
"作词", #触发词,对于没有触发词,而是由头尾实体直接触发的关系,可为null
],
"trig_type": "trigger", #trigger表明由触发词触发,tail表明为尾实体触发
"reverse": False, #是否为反向配置,即尾实体实际是头,头实体实际是尾
"trig_direction": "B", #触发P的方向,表示在自然表达中,尾实体在触发词的哪一边,L为左,R为右,B为双向都有可能,默认为B
"rel_group": "创作" #对应的反关系,即头尾实体对调后,对应的关系,用于逻辑推断
}]
>>> wordtag_ie.set_schema(schema)
>>> pprint(wordtag_ie('《忘了所有》是一首由王杰作词、作曲并演唱的歌曲,收录在专辑同名《忘了所有》中,由波丽佳音唱片于1996年08月31日发行。')[1])
[[{'GROUP': '创作',
'HEAD_ROLE': {'item': '王杰', 'offset': 10, 'type': '人物类_实体'},
'SRC': 'REVERSE',
'TAIL_ROLE': [{'item': '忘了所有', 'offset': 1, 'type': '作品类_实体'}],
'TRIG': [{'item': '作词', 'offset': 12}]},
{'GROUP': '创作者',
'HEAD_ROLE': {'item': '忘了所有', 'offset': 1, 'type': '作品类_实体'},
'SRC': 'HTG',
'TAIL_ROLE': [{'item': '王杰', 'offset': 10, 'type': '人物类_实体'}],
'TRIG': [{'item': '作词', 'offset': 12}]}]]
具体的 WordTag-IE 信息抽取的功能可以见WordTag-IE 具体介绍 .
名词短语标注#
>>> from paddlenlp import Taskflow
>>> nptag = Taskflow("knowledge_mining", model="nptag")
>>> nptag("糖醋排骨")
[{'text': '糖醋排骨', 'label': '菜品'}]
>>> nptag(["糖醋排骨", "红曲霉菌"])
[{'text': '糖醋排骨', 'label': '菜品'}, {'text': '红曲霉菌', 'label': '微生物'}]
# 使用`linking`输出粗粒度类别标签`category`,即WordTag的词汇标签。
>>> nptag = Taskflow("knowledge_mining", model="nptag", linking=True)
>>> nptag(["糖醋排骨", "红曲霉菌"])
[{'text': '糖醋排骨', 'label': '菜品', 'category': '饮食类_菜品'}, {'text': '红曲霉菌', 'label': '微生物', 'category': '生物类_微生物'}]
可配置参数说明:
batch_size:批处理大小,请结合机器情况进行调整,默认为1。max_seq_len:最大序列长度,默认为64。linking:实现与 WordTag 类别标签的 linking,默认为 False。task_path:自定义任务路径,默认为 None。
文本纠错#
融合拼音特征的端到端文本纠错模型 ERNIE-CSC
支持单条、批量预测#
>>> from paddlenlp import Taskflow
>>> corrector = Taskflow("text_correction")
# 单条输入
>>> corrector('遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。')
[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', 'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇。', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]
# 批量预测
>>> corrector(['遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。'])
[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', 'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇。', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}, {'source': '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。', 'target': '人生就是如此,经过磨练才能让自己更加茁壮,才能使自己更加乐观。', 'errors': [{'position': 18, 'correction': {'拙': '茁'}}]}]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。task_path:自定义任务路径,默认为 None。
文本相似度#
基于百万量级 Dureader Retrieval 数据集训练 RocketQA 并达到前沿文本相似效果
单条输入#
Query-Query 的相似度匹配
>>> from paddlenlp import Taskflow
>>> similarity = Taskflow("text_similarity")
>>> similarity([["春天适合种什么花?", "春天适合种什么菜?"]])
[{'text1': '春天适合种什么花?', 'text2': '春天适合种什么菜?', 'similarity': 0.83402544}]
Query-Passage 的相似度匹配
>>> similarity = Taskflow("text_similarity", model='rocketqa-base-cross-encoder')
>>> similarity([["国家法定节假日共多少天?", "现在法定假日是元旦1天,春节3天,清明节1天,五一劳动节1天,端午节1天,国庆节3天,中秋节1天,共计11天。法定休息日每年52个周末总共104天。合到一起总计115天。"]])
[{'text1': '国家法定节假日共多少天?', 'text2': '现在法定假日是元旦1天,春节3天,清明节1天,五一劳动节1天,端午节1天,国庆节3天,中秋节1天,共计11天。法定休息日每年52个周末总共104天。合到一起总计115天。', 'similarity': 0.7174624800682068}]
批量样本输入,平均速度更快#
Query-Query 的相似度匹配
>>> from paddlenlp import Taskflow
>>> similarity = Taskflow("text_similarity")
>>> similarity([['春天适合种什么花?','春天适合种什么菜?'],['谁有狂三这张高清的','这张高清图,谁有']])
[{'text1': '春天适合种什么花?', 'text2': '春天适合种什么菜?', 'similarity': 0.83402544}, {'text1': '谁有狂三这张高清的', 'text2': '这张高清图,谁有', 'similarity': 0.6540646}]
Query-Passage 的相似度匹配
>>> similarity = Taskflow("text_similarity", model='rocketqa-base-cross-encoder')
>>> similarity([["国家法定节假日共多少天?", "现在法定假日是元旦1天,春节3天,清明节1天,五一劳动节1天,端午节1天,国庆节3天,中秋节1天,共计11天。法定休息日每年52个周末总共104天。合到一起总计115天。"],["衡量酒水的价格的因素有哪些?", "衡量酒水的价格的因素很多的,酒水的血统(也就是那里产的,采用什么工艺等);存储的时间等等,酒水是一件很难标准化得商品,只要你敢要价,有买的那就值那个钱。"]])
[{'text1': '国家法定节假日共多少天?', 'text2': '现在法定假日是元旦1天,春节3天,清明节1天,五一劳动节1天,端午节1天,国庆节3天,中秋节1天,共计11天。法定休息日每年52个周末总共104天。合到一起总计115天。', 'similarity': 0.7174624800682068}, {'text1': '衡量酒水的价格的因素有哪些?', 'text2': '衡量酒水的价格的因素很多的,酒水的血统(也就是那里产的,采用什么工艺等);存储的时间等等,酒水是一件很难标准化得商品,只要你敢要价,有买的那就值那个钱。', 'similarity': 0.9069755673408508}]
模型选择#
多模型选择,满足精度、速度要求
| 模型 | 结构 | 语言 |
|---|---|---|
rocketqa-zh-dureader-cross-encoder |
12-layers, 768-hidden, 12-heads | 中文 |
simbert-base-chinese (默认) |
12-layers, 768-hidden, 12-heads | 中文 |
rocketqa-base-cross-encoder |
12-layers, 768-hidden, 12-heads | 中文 |
rocketqa-medium-cross-encoder |
6-layers, 768-hidden, 12-heads | 中文 |
rocketqa-mini-cross-encoder |
6-layers, 384-hidden, 12-heads | 中文 |
rocketqa-micro-cross-encoder |
4-layers, 384-hidden, 12-heads | 中文 |
rocketqa-nano-cross-encoder |
4-layers, 312-hidden, 12-heads | 中文 |
rocketqav2-en-marco-cross-encoder |
12-layers, 768-hidden, 12-heads | 英文 |
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。max_seq_len:最大序列长度,默认为384。task_path:自定义任务路径,默认为 None。
情感分析#
集成 BiLSTM、SKEP、UIE 等模型,支持评论维度、观点抽取、情感极性分类等情感分析任务
支持不同模型,速度快和精度高两种模式#
>>> from paddlenlp import Taskflow
# 默认使用bilstm模型进行预测,速度快
>>> senta = Taskflow("sentiment_analysis")
>>> senta("这个产品用起来真的很流畅,我非常喜欢")
[{'text': '这个产品用起来真的很流畅,我非常喜欢', 'label': 'positive', 'score': 0.9938690066337585}]
# 使用SKEP情感分析预训练模型进行预测,精度高
>>> senta = Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch")
>>> senta("作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。")
[{'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。', 'label': 'positive', 'score': 0.984320878982544}]
# 使用UIE模型进行情感分析,具有较强的样本迁移能力
# 1. 语句级情感分析
>>> schema = ['情感倾向[正向,负向]']
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta('蛋糕味道不错,店家服务也很好')
[{'情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.996646058824652}]}]
# 2. 评价维度级情感分析
>>> # Aspect Term Extraction
>>> # schema = ["评价维度"]
>>> # Aspect - Opinion Extraction
>>> # schema = [{"评价维度":["观点词"]}]
>>> # Aspect - Sentiment Extraction
>>> # schema = [{"评价维度":["情感倾向[正向,负向,未提及]"]}]
>>> # Aspect - Sentiment - Opinion Extraction
>>> schema = [{"评价维度":["观点词", "情感倾向[正向,负向,未提及]"]}]
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta('蛋糕味道不错,店家服务也很热情')
[{'评价维度': [{'text': '服务', 'start': 9, 'end': 11, 'probability': 0.9709093024793489, 'relations': { '观点词': [{'text': '热情', 'start': 13, 'end': 15, 'probability': 0.9897222206316556}], '情感倾向[正向,负向,未提及]': [{'text': '正向', 'probability': 0.9999327669598301}]}}, {'text': '味道', 'start': 2, 'end': 4, 'probability': 0.9105472387838915, 'relations': {'观点词': [{'text': '不错', 'start': 4, 'end': 6, 'probability': 0.9946981266891619}], '情感倾向[正向,负向,未提及]': [{'text': '正向', 'probability': 0.9998829392709467}]}}]}]
批量样本输入,平均速度更快#
>>> from paddlenlp import Taskflow
>>> schema = [{"评价维度":["观点词", "情感倾向[正向,负向,未提及]"]}]
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta(["房间不大,很干净", "老板服务热情,价格也便宜"])
[{'评价维度': [{'text': '房间', 'start': 0, 'end': 2, 'probability': 0.998526653966298, 'relations': {'观点词': [{'text': '干净', 'start': 6, 'end': 8, 'probability': 0.9899580841973474}, {'text': '不大', 'start': 2, 'end': 4, 'probability': 0.9945525066163512}], '情感倾向[正向,负向,未提及]': [{'text': '正向', 'probability': 0.6077412795680956}]}}]}, {'评价维度': [{'text': '服务', 'start': 2, 'end': 4, 'probability': 0.9913965811617516, 'relations': {'观点词': [{'text': '热情', 'start': 4, 'end': 6, 'probability': 0.9995530034336753}], '情感倾向[正向,负向,未提及]': [{'text': '正向', 'probability': 0.9956709542206106}]}}, {'text': '价格', 'start': 7, 'end': 9, 'probability': 0.9970075537913772, 'relations': {'观点词': [{'text': '便宜', 'start': 10, 'end': 12, 'probability': 0.9991568497876635}], '情感倾向[正向,负向,未提及]': [{'text': '正向', 'probability': 0.9943191048602245}]}}]}]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。model:选择任务使用的模型,可选有bilstm,skep_ernie_1.0_large_ch,uie-senta-base,uie-senta-medium,uie-senta-mini,uie-senta-micro,uie-senta-nano。task_path:自定义任务路径,默认为 None。
生成式问答#
使用最大中文开源 CPM 模型完成问答
支持单条、批量预测#
>>> from paddlenlp import Taskflow
>>> qa = Taskflow("question_answering")
# 单条输入
>>> qa("中国的国土面积有多大?")
[{'text': '中国的国土面积有多大?', 'answer': '960万平方公里。'}]
# 多条输入
>>> qa(["中国国土面积有多大?", "中国的首都在哪里?"])
[{'text': '中国国土面积有多大?', 'answer': '960万平方公里。'}, {'text': '中国的首都在哪里?', 'answer': '北京。'}]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。
智能写诗#
使用最大中文开源 CPM 模型完成写诗
支持单条、批量预测#
>>> from paddlenlp import Taskflow
>>> poetry = Taskflow("poetry_generation")
# 单条输入
>>> poetry("林密不见人")
[{'text': '林密不见人', 'answer': ',但闻人语响。'}]
# 多条输入
>>> poetry(["林密不见人", "举头邀明月"])
[{'text': '林密不见人', 'answer': ',但闻人语响。'}, {'text': '举头邀明月', 'answer': ',低头思故乡。'}]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。
开放域对话#
十亿级语料训练最强中文闲聊模型 PLATO-Mini,支持多轮对话
非交互模式#
>>> from paddlenlp import Taskflow
>>> dialogue = Taskflow("dialogue")
>>> dialogue(["吃饭了吗"])
['刚吃完饭,你在干什么呢?']
>>> dialogue(["你好", "吃饭了吗"], ["你是谁?"])
['吃过了,你呢', '我是李明啊']
可配置参数:
batch_size:批处理大小,请结合机器情况进行调整,默认为1。max_seq_len:最大序列长度,默认为512。
交互模式#
>>> from paddlenlp import Taskflow
>>> dialogue = Taskflow("dialogue")
# 输入`exit`可退出交互模式
>>> dialogue.interactive_mode(max_turn=3)
'''
[Human]:你好
[Bot]:你好,很高兴认识你,我想问你一下,你喜欢运动吗?
[Human]:喜欢
[Bot]:那你喜欢什么运动啊?
[Human]:篮球,你喜欢篮球吗
[Bot]:当然了,我很喜欢打篮球的
'''
交互模式参数:
max_turn:任务能记忆的对话轮数,当 max_turn 为1时,模型只能记住当前对话,无法获知之前的对话内容。
代码生成#
通过 CodeGen 模型来生成代码
支持单条、批量预测#
>>> from paddlenlp import Taskflow
# 默认模型为 Salesforce/codegen-350M-mono
>>> codegen = Taskflow("code_generation", model="Salesforce/codegen-2B-mono")
# 单条输入
>>> codegen("def hello_world():")
['\n print("Hello World")']
# 多条输入
>>> codegen(["Get the length of array", "def hello_world():"])
['\n n = len(a)\n\n #', '\n print("Hello World!")']
可配置参数说明#
model:可选模型,默认为 Salesforce/codegen-350M-mono,支持的模型参考CodeGen 文档。batch_size:批处理大小,请结合机器情况进行调整,默认为1。max_length:生成代码的最大长度,默认为128。min_length:生成代码的最小长度,默认为0。decode_strategy:解码策略,支持 greedy_search,beam_search 和 sampling,默认为 sampling。temperature:解码参数 temperature,默认为0.6。top_k:解码参数 top_k,默认为5。top_p:解码参数 top_p,默认为1.0。num_beams:beam_search 解码的 beam size,默认为4。length_penalty:解码长度控制值,默认为1.0。repetition_penalty:解码重复惩罚值,默认为1.1。output_scores:是否要输出解码得分,请默认为 False。
文本摘要#
通过 Pegasus 模型来生成摘要
支持单条、批量预测#
>>> from paddlenlp import Taskflow
>>> summarizer = Taskflow("text_summarization")
# 单条输入
>>> summarizer('2022年,中国房地产进入转型阵痛期,传统“高杠杆、快周转”的模式难以为继,万科甚至直接喊话,中国房地产进入“黑铁时代”')
# 输出:['万科喊话中国房地产进入“黑铁时代”']
# 多条输入
>>> summarizer([
'据悉,2022年教育部将围绕“巩固提高、深化落实、创新突破”三个关键词展开工作。要进一步强化学校教育主阵地作用,继续把落实“双减”作为学校工作的重中之重,重点从提高作业设计水平、提高课后服务水平、提高课堂教学水平、提高均衡发展水平四个方面持续巩固提高学校“双减”工作水平。',
'党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。'
])
#输出:['教育部:将从四个方面持续巩固提高学校“双减”工作水平', '党参能降低三高的危害']
可配置参数说明#
model:可选模型,默认为IDEA-CCNL/Randeng-Pegasus-523M-Summary-Chinese。batch_size:批处理大小,请结合机器情况进行调整,默认为1。
文档智能#
以多语言跨模态布局增强文档预训练模型 ERNIE-Layout 为核心底座
输入格式#
[
{"doc": "./invoice.jpg", "prompt": ["发票号码是多少?", "校验码是多少?"]},
{"doc": "./resume.png", "prompt": ["五百丁本次想要担任的是什么职位?", "五百丁是在哪里上的大学?", "大学学的是什么专业?"]}
]
默认使用 PaddleOCR 进行 OCR 识别,同时支持用户通过word_boxes传入自己的 OCR 结果,格式为List[str, List[float, float, float, float]]。
[
{"doc": doc_path, "prompt": prompt, "word_boxes": word_boxes}
]
支持单条、批量预测#
支持本地图片路径输入

>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> docprompt = Taskflow("document_intelligence")
>>> pprint(docprompt([{"doc": "./resume.png", "prompt": ["五百丁本次想要担任的是什么职位?", "五百丁是在哪里上的大学?", "大学学的是什么专业?"]}]))
[{'prompt': '五百丁本次想要担任的是什么职位?',
'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},
{'prompt': '五百丁是在哪里上的大学?',
'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},
{'prompt': '大学学的是什么专业?',
'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]
http 图片链接输入

>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> docprompt = Taskflow("document_intelligence")
>>> pprint(docprompt([{"doc": "https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg", "prompt": ["发票号码是多少?", "校验码是多少?"]}]))
[{'prompt': '发票号码是多少?',
'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]},
{'prompt': '校验码是多少?',
'result': [{'end': 233,
'prob': 1.0,
'start': 231,
'value': '01107 555427109891646'}]}]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。lang:选择 PaddleOCR 的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。topn: 如果模型识别出多个结果,将返回前 n 个概率值最高的结果,默认为1。
问题生成#
基于百度自研中文预训练模型 UNIMO-Text 和大规模多领域问题生成数据集
支持单条、批量预测#
>>> from paddlenlp import Taskflow
# 默认模型为 unimo-text-1.0-dureader_qg
>>> question_generator = Taskflow("question_generation")
# 单条输入
>>> question_generator([
{"context": "奇峰黄山千米以上的山峰有77座,整座黄山就是一座花岗岩的峰林,自古有36大峰,36小峰,最高峰莲花峰、最险峰天都峰和观日出的最佳点光明顶构成黄山的三大主峰。", "answer": "莲花峰"}
])
'''
['黄山最高峰是什么']
'''
# 多条输入
>>> question_generator([
{"context": "奇峰黄山千米以上的山峰有77座,整座黄山就是一座花岗岩的峰林,自古有36大峰,36小峰,最高峰莲花峰、最险峰天都峰和观日出的最佳点光明顶构成黄山的三大主峰。", "answer": "莲花峰"},
{"context": "弗朗索瓦·韦达外文名:franciscusvieta国籍:法国出生地:普瓦图出生日期:1540年逝世日期:1603年12月13日职业:数学家主要成就:为近代数学的发展奠定了基础。", "answer": "法国"}
])
'''
['黄山最高峰是什么', '弗朗索瓦是哪里人']
'''
可配置参数说明#
model:可选模型,默认为 unimo-text-1.0-dureader_qg,支持的模型有["unimo-text-1.0", "unimo-text-1.0-dureader_qg", "unimo-text-1.0-question-generation", "unimo-text-1.0-question-generation-dureader_qg"]。device:运行设备,默认为"gpu"。template:模版,可选项有[0, 1, 2, 3],1表示使用默认模版,0表示不使用模版。batch_size:批处理大小,请结合机器情况进行调整,默认为1。output_scores:是否要输出解码得分,默认为 False。is_select_from_num_return_sequences:是否对多个返回序列挑选最优项输出,当为 True 时,若 num_return_sequences 不为1则自动根据解码得分选择得分最高的序列最为最终结果,否则返回 num_return_sequences 个序列,默认为 True。max_length:生成代码的最大长度,默认为50。min_length:生成代码的最小长度,默认为3。decode_strategy:解码策略,支持 beam_search 和 sampling,默认为 beam_search。temperature:解码参数 temperature,默认为1.0。top_k:解码参数 top_k,默认为0。top_p:解码参数 top_p,默认为1.0。num_beams:解码参数 num_beams,表示 beam_search 解码的 beam size,默认为6。num_beam_groups:解码参数 num_beam_groups,默认为1。diversity_rate:解码参数 diversity_rate,默认为0.0。length_penalty:解码长度控制值,默认为1.2。num_return_sequences:解码返回序列数,默认为1。repetition_penalty:解码重复惩罚值,默认为1。use_fast:表示是否开启基于 FastGeneration 的高性能预测,注意 FastGeneration 的高性能预测仅支持 gpu,默认为 False。use_fp16_decoding: 表示在开启高性能预测的时候是否使用 fp16来完成预测过程,若不使用则使用 fp32,默认为 False。
零样本文本分类#
适配多场景的零样本通用文本分类工具
通用文本分类主要思想是利用单一模型支持通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等众多“泛分类”任务。用户可以自定义任意标签组合,在不限定领域、不设定 prompt 的情况下进行文本分类。
情感分析#
>>> cls = Taskflow("zero_shot_text_classification", schema=["这是一条好评", "这是一条差评"])
>>> cls("房间干净明亮,非常不错")
[{'predictions': [{'label': '这是一条好评', 'score': 0.9072999699439914}], 'text_a': '房间干净明亮,非常不错'}]
>>> cls("东西还可以,但是快递非常慢,下次不会再买这家了。")
[{'predictions': [{'label': '这是一条差评', 'score': 0.9282672873429476}], 'text_a': '东西还可以,但是快递非常慢,下次不会再买这家了。'}]
意图识别#
>>> from paddlenlp import Taskflow
>>> schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用"]
>>> cls("先天性厚甲症去哪里治")
[{'predictions': [{'label': '就医建议', 'score': 0.5494891306403806}], 'text_a': '先天性厚甲症去哪里治'}]
>>> cls("男性小腹疼痛是什么原因?")
[{'predictions': [{'label': '病因分析', 'score': 0.5763229815300723}], 'text_a': '男性小腹疼痛是什么原因?'}]
语义相似度计算#
>>> from paddlenlp import Taskflow
>>> cls = Taskflow("zero_shot_text_classification", schema=["不同", "相同"])
>>> cls([["怎么查看合同", "从哪里可以看到合同"]])
[{'predictions': [{'label': '相同', 'score': 0.9951385264364382}], 'text_a': '怎么查看合同', 'text_b': '从哪里可以看到合同'}]
>>> cls([["为什么一直没有电话来确认借款信息", "为何我还款了,今天却接到客服电话通知"]])
[{'predictions': [{'label': '不同', 'score': 0.9991497973466908}], 'text_a': '为什么一直没有电话来确认借款信息', 'text_b': '为何我还款了,今天却接到客服电话通知'}]
蕴含推理#
>>> from paddlenlp import Taskflow
>>> cls = Taskflow("zero_shot_text_classification", schema=["无关", "蕴含", "矛盾"])
>>> cls([["一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。", "骑自行车的人正朝钟楼走去。"]])
[{'predictions': [{'label': '蕴含', 'score': 0.9931122738524856}], 'text_a': '一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。', 'text_b': '骑自行车的人正朝钟楼走去。'}]
>>> cls([["一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。", "这件衬衫是新的。"]])
[{'predictions': [{'label': '无关', 'score': 0.997680189334587}], 'text_a': '一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。', 'text_b': '这件衬衫是新的。'}]
>>> cls([["一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。", "两人都穿着白色裤子。"]])
[{'predictions': [{'label': '矛盾', 'score': 0.9666946163628479}], 'text_a': '一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。', 'text_b': '两人都穿着白色裤子。'}]
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。task_path:自定义任务路径,默认为 None。schema:定义任务标签候选集合。model:选择任务使用的模型,默认为utc-base, 支持utc-xbase,utc-base,utc-medium,utc-micro,utc-mini,utc-nano,utc-pico。max_seq_len:最长输入长度,包括所有标签的长度,默认为512。pred_threshold:模型对标签预测的概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装 NVIDIA 相关驱动和基础软件,确保 CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保 GPU 设备的 CUDA 计算能力(CUDA Compute Capability)大于7.0,典型的设备包括 V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于 CUDA Compute Capability 和精度支持情况请参考 NVIDIA 文档:GPU 硬件与支持精度对照表。
模型特征提取#
基于百度自研中文图文跨模态预训练模型 ERNIE-ViL 2.0
多模态特征提取#
>>> from paddlenlp import Taskflow
>>> from PIL import Image
>>> import paddle.nn.functional as F
>>> vision_language= Taskflow("feature_extraction")
# 单条输入
>>> image_embeds = vision_language(Image.open("demo/000000039769.jpg"))
>>> image_embeds["features"]
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[-0.59475428, -0.69795364, 0.22144008, 0.88066685, -0.58184201,
# 单条输入
>>> text_embeds = vision_language("猫的照片")
>>> text_embeds['features']
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.04250504, -0.41429776, 0.26163983, 0.29910022, 0.39019185,
-0.41884750, -0.19893740, 0.44328332, 0.08186490, 0.10953025,
......
# 多条输入
>>> image_embeds = vision_language([Image.open("demo/000000039769.jpg")])
>>> image_embeds["features"]
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[-0.59475428, -0.69795364, 0.22144008, 0.88066685, -0.58184201,
......
# 多条输入
>>> text_embeds = vision_language(["猫的照片","狗的照片"])
>>> text_embeds["features"]
Tensor(shape=[2, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.04250504, -0.41429776, 0.26163983, ..., 0.26221892,
0.34387422, 0.18779707],
[ 0.06672225, -0.41456309, 0.13787819, ..., 0.21791610,
0.36693242, 0.34208685]])
>>> image_features = image_embeds["features"]
>>> text_features = text_embeds["features"]
>>> image_features /= image_features.norm(axis=-1, keepdim=True)
>>> text_features /= text_features.norm(axis=-1, keepdim=True)
>>> logits_per_image = 100 * image_features @ text_features.t()
>>> probs = F.softmax(logits_per_image, axis=-1)
>>> probs
Tensor(shape=[1, 2], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[0.99833173, 0.00166824]])
模型选择#
多模型选择,满足精度、速度要求
| 模型 | 视觉 | 文本 | 语言 |
|---|---|---|---|
PaddlePaddle/ernie_vil-2.0-base-zh (默认) |
ViT | ERNIE | 中文 |
OFA-Sys/chinese-clip-vit-base-patch16 |
ViT-B/16 | RoBERTa-wwm-Base | 中文 |
OFA-Sys/chinese-clip-vit-large-patch14 |
ViT-L/14 | RoBERTa-wwm-Base | 中文 |
OFA-Sys/chinese-clip-vit-large-patch14-336px |
ViT-L/14 | RoBERTa-wwm-Base | 中文 |
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。_static_mode:静态图模式,默认开启。model:选择任务使用的模型,默认为PaddlePaddle/ernie_vil-2.0-base-zh。
文本特征提取#
>>> from paddlenlp import Taskflow
>>> import paddle.nn.functional as F
>>> text_encoder = Taskflow("feature_extraction", model='rocketqa-zh-base-query-encoder')
>>> text_embeds = text_encoder(['春天适合种什么花?','谁有狂三这张高清的?'])
>>> text_features1 = text_embeds["features"]
>>> text_features1
Tensor(shape=[2, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.27640465, -0.13405125, 0.00612330, ..., -0.15600294,
-0.18932408, -0.03029604],
[-0.12041329, -0.07424965, 0.07895312, ..., -0.17068857,
0.04485796, -0.18887770]])
>>> text_embeds = text_encoder('春天适合种什么菜?')
>>> text_features2 = text_embeds["features"]
>>> text_features2
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.32578075, -0.02398480, -0.18929179, -0.18639392, -0.04062131,
......
>>> probs = F.cosine_similarity(text_features1, text_features2)
>>> probs
Tensor(shape=[2], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[0.86455142, 0.41222256])
模型选择#
多模型选择,满足精度、速度要求
| 模型 | 层数 | 维度 | 语言 |
|---|---|---|---|
rocketqa-zh-dureader-query-encoder |
12 | 768 | 中文 |
rocketqa-zh-dureader-para-encoder |
12 | 768 | 中文 |
rocketqa-zh-base-query-encoder |
12 | 768 | 中文 |
rocketqa-zh-base-para-encoder |
12 | 768 | 中文 |
moka-ai/m3e-base |
12 | 768 | 中文 |
rocketqa-zh-medium-query-encoder |
6 | 768 | 中文 |
rocketqa-zh-medium-para-encoder |
6 | 768 | 中文 |
rocketqa-zh-mini-query-encoder |
6 | 384 | 中文 |
rocketqa-zh-mini-para-encoder |
6 | 384 | 中文 |
rocketqa-zh-micro-query-encoder |
4 | 384 | 中文 |
rocketqa-zh-micro-para-encoder |
4 | 384 | 中文 |
rocketqa-zh-nano-query-encoder |
4 | 312 | 中文 |
rocketqa-zh-nano-para-encoder |
4 | 312 | 中文 |
rocketqav2-en-marco-query-encoder |
12 | 768 | 英文 |
rocketqav2-en-marco-para-encoder |
12 | 768 | 英文 |
ernie-search-base-dual-encoder-marco-en" |
12 | 768 | 英文 |
可配置参数说明#
batch_size:批处理大小,请结合机器情况进行调整,默认为1。max_seq_len:文本序列的最大长度,默认为128。return_tensors: 返回的类型,有 pd 和 np,默认为 pd。model:选择任务使用的模型,默认为PaddlePaddle/ernie_vil-2.0-base-zh。pooling_mode:选择句向量获取方式,有'max_tokens','mean_tokens','mean_sqrt_len_tokens','cls_token',默认为'cls_token'(moka-ai/m3e-base)。
PART Ⅱ 定制化训练#
适配任务列表
如果你有自己的业务数据集,可以对模型效果进一步调优,支持定制化训练的任务如下:
| 任务名称 | 默认路径 | |
|---|---|---|
Taskflow("word_segmentation", mode="base") |
$HOME/.paddlenlp/taskflow/lac |
示例 |
Taskflow("word_segmentation", mode="accurate") |
$HOME/.paddlenlp/taskflow/wordtag |
示例 |
Taskflow("pos_tagging") |
$HOME/.paddlenlp/taskflow/lac |
示例 |
Taskflow("ner", mode="fast") |
$HOME/.paddlenlp/taskflow/lac |
示例 |
Taskflow("ner", mode="accurate") |
$HOME/.paddlenlp/taskflow/wordtag |
示例 |
Taskflow("information_extraction", model="uie-base") |
$HOME/.paddlenlp/taskflow/information_extraction/uie-base |
示例 |
Taskflow("information_extraction", model="uie-tiny") |
$HOME/.paddlenlp/taskflow/information_extraction/uie-tiny |
示例 |
Taskflow("dependency_parsing", model="ddparser") |
$HOME/.paddlenlp/taskflow/dependency_parsing/ddparser |
示例 |
Taskflow("dependency_parsing", model="ddparser-ernie-1.0") |
$HOME/.paddlenlp/taskflow/dependency_parsing/ddparser-ernie-1.0 |
示例 |
Taskflow("dependency_parsing", model="ddparser-ernie-gram-zh") |
$HOME/.paddlenlp/taskflow/dependency_parsing/ddparser-ernie-gram-zh |
示例 |
Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch") |
$HOME/.paddlenlp/taskflow/sentiment_analysis/skep_ernie_1.0_large_ch |
示例 |
Taskflow("knowledge_mining", model="wordtag") |
$HOME/.paddlenlp/taskflow/wordtag |
示例 |
Taskflow("knowledge_mining", model="nptag") |
$HOME/.paddlenlp/taskflow/knowledge_mining/nptag |
示例 |
Taskflow("zero_shot_text_classification", model="utc-base") |
$HOME/.paddlenlp/taskflow/zero_shot_text_classification/utc-base |
示例 |
定制化训练示例
这里我们以命名实体识别Taskflow("ner", mode="accurate")为例,展示如何定制自己的模型。
调用Taskflow接口后,程序自动将相关文件下载到$HOME/.paddlenlp/taskflow/wordtag/,该默认路径包含以下文件:
$HOME/.paddlenlp/taskflow/wordtag/
├── model_state.pdparams # 默认模型参数文件
├── model_config.json # 默认模型配置文件
└── tags.txt # 默认标签文件
参考上表中对应示例准备数据集和标签文件
tags.txt,执行相应训练脚本得到自己的model_state.pdparams和model_config.json。根据自己数据集情况,修改标签文件
tags.txt。将以上文件保存到任意路径中,自定义路径下的文件需要和默认路径的文件一致:
custom_task_path/
├── model_state.pdparams # 定制模型参数文件
├── model_config.json # 定制模型配置文件
└── tags.txt # 定制标签文件
通过
task_path指定自定义路径,使用 Taskflow 加载自定义模型进行一键预测:
from paddlenlp import Taskflow
my_ner = Taskflow("ner", mode="accurate", task_path="./custom_task_path/")
模型算法#
模型算法说明
| 任务名称 | 模型 | 模型详情 | 训练集 |
| 中文分词 | 默认模式: BiGRU+CRF | 训练详情 | 百度自建数据集,包含近2200万句子,覆盖多种场景 |
| 快速模式:Jieba | - | - | |
| 精确模式:WordTag | 训练详情 | 百度自建数据集,词类体系基于 TermTree 构建 | |
| 词性标注 | BiGRU+CRF | 训练详情 | 百度自建数据集,包含2200万句子,覆盖多种场景 |
| 命名实体识别 | 精确模式:WordTag | 训练详情 | 百度自建数据集,词类体系基于 TermTree 构建 |
| 快速模式:BiGRU+CRF | 训练详情 | 百度自建数据集,包含2200万句子,覆盖多种场景 | |
| 依存句法分析 | DDParser | 训练详情 | 百度自建数据集,DuCTB 1.0中文依存句法树库 |
| 信息抽取 | UIE | 训练详情 | 百度自建数据集 |
| 解语知识标注 | 词类知识标注:WordTag | 训练详情 | 百度自建数据集,词类体系基于 TermTree 构建 |
| 名词短语标注:NPTag | 训练详情 | 百度自建数据集 | |
| 文本相似度 | SimBERT | - | 收集百度知道2200万对相似句组 |
| 情感分析 | BiLSTM | - | 百度自建数据集 |
| SKEP | 训练详情 | 百度自建数据集 | |
| UIE | 训练详情 | 百度自建数据集 | |
| 生成式问答 | CPM | - | 100GB 级别中文数据 |
| 智能写诗 | CPM | - | 100GB 级别中文数据 |
| 开放域对话 | PLATO-Mini | - | 十亿级别中文对话数据 |
| 零样本文本分类 | UTC | 训练详情 | 百度自建数据集 |
FAQ#
Q:Taskflow 如何修改任务保存路径?
A: Taskflow 默认会将任务相关模型等文件保存到$HOME/.paddlenlp下,可以在任务初始化的时候通过home_path自定义修改保存路径。示例:
from paddlenlp import Taskflow
ner = Taskflow("ner", home_path="/workspace")
通过以上方式即可将 ner 任务相关文件保存至/workspace路径下。
Q:下载或调用模型失败,多次下载均失败怎么办?
A: Taskflow 默认会将任务相关模型等文件保存到$HOME/.paddlenlp/taskflow下,如果下载或调用失败,可删除相应路径下的文件,重新尝试即可
Q:Taskflow 如何提升预测速度?
A: 可以结合设备情况适当调整 batch_size,采用批量输入的方式来提升平均速率。示例:
from paddlenlp import Taskflow
# 精确模式模型体积较大,可结合机器情况适当调整batch_size,采用批量样本输入的方式。
seg_accurate = Taskflow("word_segmentation", mode="accurate", batch_size=32)
# 批量样本输入,输入为多个句子组成的list,预测速度更快
texts = ["热梅茶是一道以梅子为主要原料制作的茶饮", "《孤女》是2010年九州出版社出版的小说,作者是余兼羽"]
seg_accurate(texts)
通过上述方式进行分词可以大幅提升预测速度。
Q:后续会增加更多任务支持吗?
A: Taskflow 支持任务持续丰富中,我们将根据开发者反馈,灵活调整功能建设优先级,可通过 Issue 反馈给我们。