PaddleNLP One-Stop Prediction: Taskflow API#



![]()

QuickStart | Community | One-Stop Prediction & Custom Training | FAQ
Features#
PaddleNLP provides out-of-the-box industry-level NLP prebuilt task capabilities, requiring no training and enabling one-click prediction:
Most comprehensive Chinese tasks: Covers two core applications of natural language understanding and natural language generation;
Ultimate industry-level performance: Delivers industry-level accuracy and prediction speed across multiple Chinese scenarios;
Unified application paradigm: Through
paddlenlp.Taskflow| Task Name | Invocation Method | One-Click Prediction | Single Input | Batch Input | Document-Level Input | Custom Training | Additional Features | |:———————————–|———————————————|———————-|—————|————–|———————–|—————–|————————————————————————————–| | Chinese Word Segmentation |Taskflow("word_segmentation")| ✅ | ✅ | ✅ | ✅ | ✅ | Multiple segmentation modes for fast segmentation and entity-level precision | | Part-of-Speech Tagging |Taskflow("pos_tagging")| ✅ | ✅ | ✅ | ✅ | ✅ | Based on Baidu’s state-of-the-art lexical analysis tool LAC | | Named Entity Recognition |Taskflow("ner")| ✅ | ✅ | ✅ | ✅ | ✅ | Most comprehensive Chinese entity tag coverage | | Dependency Parsing |Taskflow("dependency_parsing")| ✅ | ✅ | ✅ | | ✅ | DDParser developed based on the largest Chinese dependency treebank | | Information Extraction |Taskflow("information_extraction")| ✅ | ✅ | ✅ | ✅ | ✅ | General-purpose information extraction tool adapted to multiple scenarios | | WordTag-Knowledge Mining |Taskflow("knowledge_mining")| ✅ | ✅ | ✅ | ✅ | ✅ | WordTag: A knowledge mining system supporting 20+ domains and 4000+ fine-grained tags | | Feature | API | Basic Usage | GPU Support | Fine-tune | X2Paddle | ONNX Inference | Description | |———————-|——————————————————————————————————————————————————-|————-|————-|———–|———–|—————-|——————————————————————————————-| | [Word Annotation](#Word Annotation) |Taskflow("word_annotation")| ✅ | ✅ | ✅ | ✅ | ✅ | Word annotation tool covering all Chinese vocabulary | | [Text Correction](#Text Correction) |Taskflow("text_correction")| ✅ | ✅ | ✅ | ✅ | ✅ | End-to-end text correction model ERNIE-CSC with pinyin features | | [Text Similarity](#Text Similarity) |Taskflow("text_similarity")| ✅ | ✅ | ✅ | | | RocketQA trained on million-scale Dureader Retrieval dataset for state-of-the-art text similarity | | [Sentiment Analysis](#Sentiment Analysis) |Taskflow("sentiment_analysis")| ✅ | ✅ | ✅ | | ✅ | Integrated models (BiLSTM, SKEP, UIE) supporting comment dimension, opinion extraction, sentiment classification | | [Generative QA](#Generative QA) |Taskflow("question_answering")| ✅ | ✅ | ✅ | | | Using largest Chinese open-source CPM model for Q&A | | [Intelligent Poetry](#Intelligent Poetry) |Taskflow("poetry_generation")| ✅ | ✅ | ✅ | | | Using largest Chinese open-source CPM model for poetry generation | | [Open-domain Dialogue](#Open-domain Dialogue) |Taskflow("dialogue")| ✅ | ✅ | ✅ | | | PLATO-Mini model trained on billion-scale corpus for Chinese multi-turn conversation | | [Code Generation](#Code Generation) |Taskflow("code_generation")| ✅ | ✅ | ✅ | | | Using code generation model to automatically generate code based on natural language input | | Code Generation |Taskflow("code_generation")| ✅ | ✅ | ✅ | ✅ | | Code Generation LLM | | Text Summarization |Taskflow("text_summarization")| ✅ | ✅ | ✅ | ✅ | | Text Summarization LLM | | Document Intelligence |Taskflow("document_intelligence")| ✅ | ✅ | ✅ | ✅ | | Powered by the multilingual cross-modal layout-enhanced document pre-training model ERNIE-Layout as the core foundation | | Question Generation |Taskflow("question_generation")| ✅ | ✅ | ✅ | ✅ | | Question Generation LLM | | Zero-shot Text Classification |Taskflow("zero_shot_text_classification")| ✅ | ✅ | ✅ | | ✅ | Integrated multi-scenario general text classification tool | | Model Feature Extraction |Taskflow("feature_extraction")| ✅ | ✅ | ✅ | ✅ | | Feature extraction tools for text and images |
QuickStart#
Environment Requirements
Python >= 3.6
PaddlePaddle >= 2.3.0
PaddleNLP >= 2.3.4
Enter Jupyter Notebook environment to experience online 👉 Enter Online Runtime
PaddleNLP Taskflow API supports continuous enrichment of tasks. We will adjust feature development priorities based on developer feedback. Please provide feedback via Questionnaire.
Community Exchange 👬#
After scanning the QR code and completing the questionnaire, join the group to receive benefits:
Get livestream course links for 《Industry-level General Information Extraction Technology UIE+ERNIE Lightweight Model》at 20:30 on May 18-19
10G 重磅 NLP 学习礼包:

Detailed Usage#
PART Ⅰ One-Stop Prediction#
Chinese Word Segmentation#
(Expand for details) Multiple segmentation modes to meet rapid splitting and entity-level precise segmentation
Three segmentation modes to meet various needs#
from paddlenlp import Taskflow
# Default mode: entity granularity segmentation, balancing accuracy and speed, based on Baidu LAC
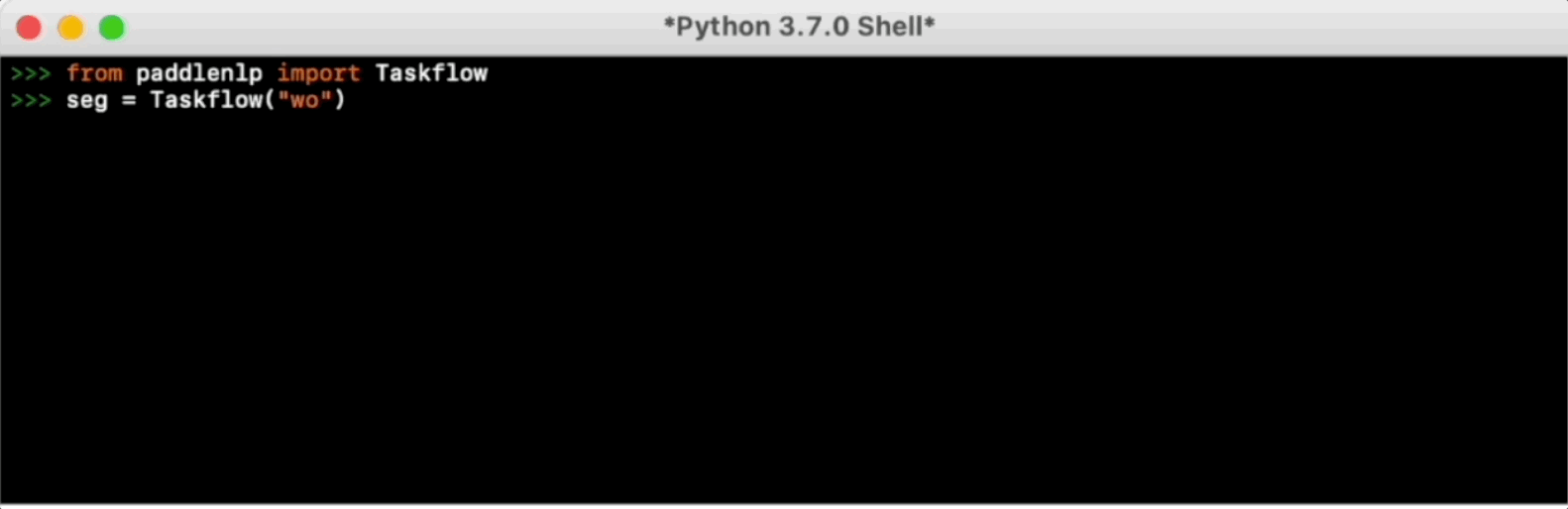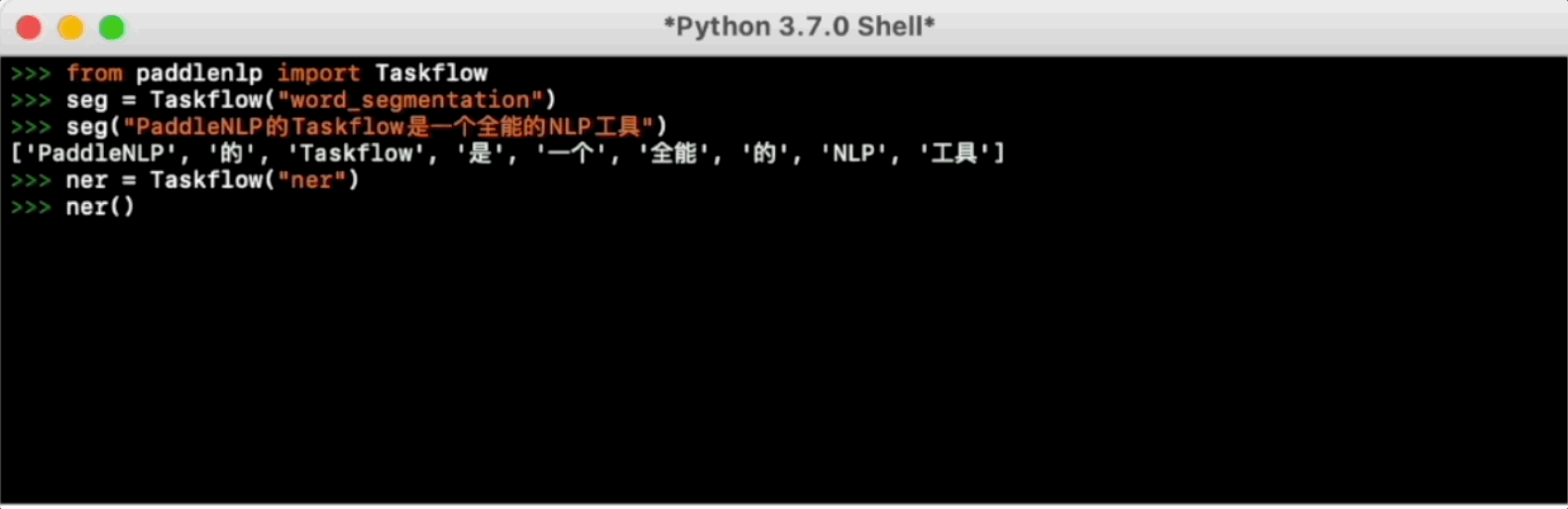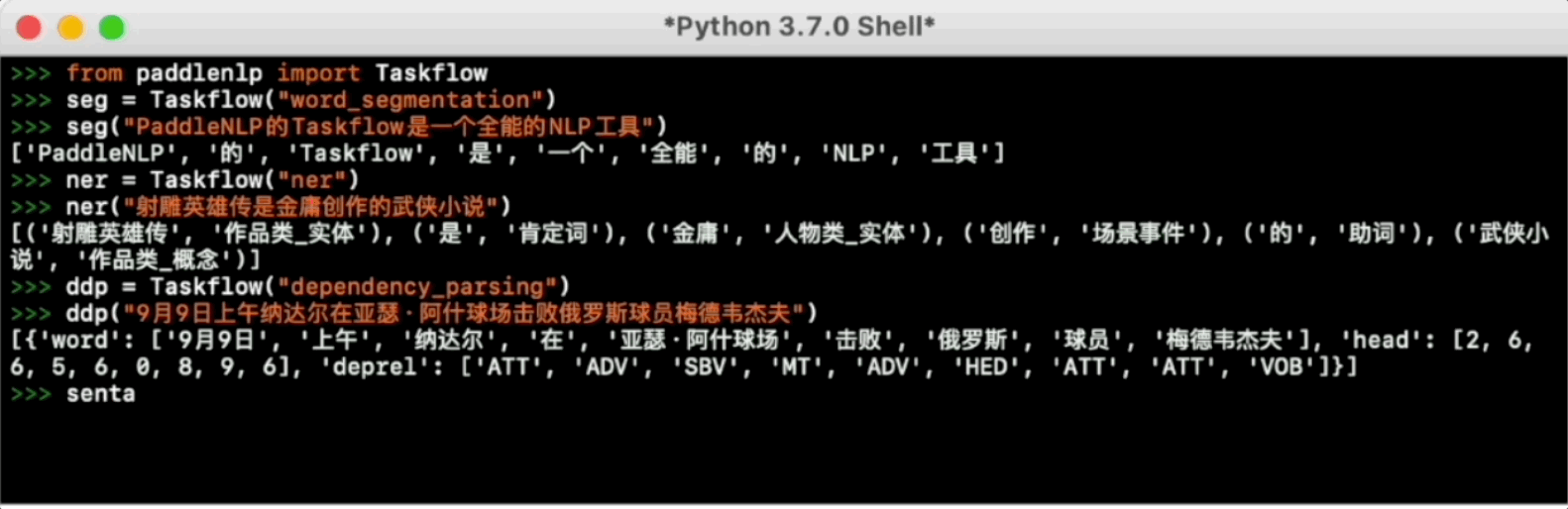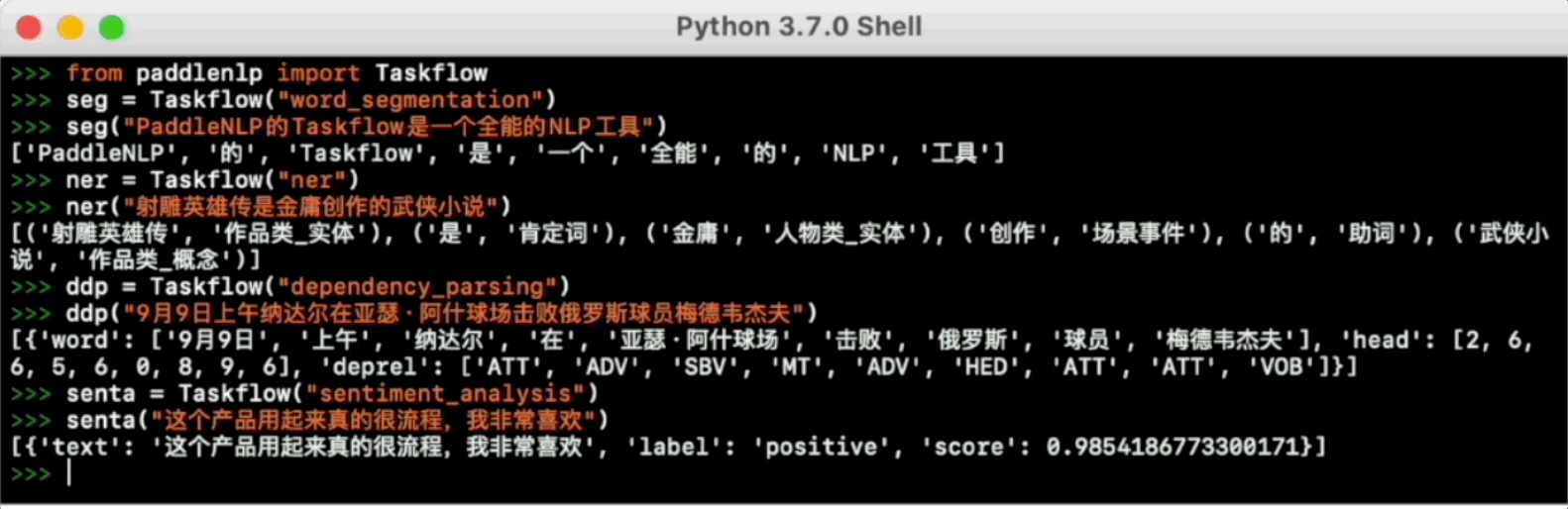
>>> seg = Taskflow("word_segmentation")
>>> seg("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
['近日', '国家卫健委', '发布', '第九版', '新型', '冠状病毒肺炎', '诊疗', '方案']
# Fast mode: fastest text segmentation, based on jieba Chinese word segmentation tool
>>> seg_fast = Taskflow("word_segmentation", mode="fast")
>>> seg_fast("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
['近日', '国家', '卫健委', '发布', '第九版', '新型', '冠状病毒', '肺炎', '诊疗', '方案']
# Accurate mode: highest entity granularity accuracy, based on Baidu Jieyu
# The accurate mode is based on pre-trained models, more suitable for entity-level segmentation needs, applicable to scenarios like knowledge graph construction and enterprise search query analysis
>>> seg_accurate = Taskflow("word_segmentation", mode="accurate")
>>> seg_accurate("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
['近日', '国家卫健委', '发布', '第九版', '新型冠状病毒肺炎', '诊疗', '方案']
Batch Input for Faster Processing#
Input as a list of multiple sentences yields faster average speed.
>>> from paddlenlp import Taskflow
>>> seg = Taskflow("word_segmentation")
>>> seg(["第十四届全运会在西安举办", "三亚是一个美丽的城市"])
[['第十四届', '全运会', '在', '西安', '举办'], ['三亚', '是', '一个', '美丽', '的', '城市']]
Custom Dictionary#
You can load custom dictionaries via the user_dict parameter to tailor segmentation results.
In default and accurate modes, each line in the dictionary file contains one or more custom items. Example dictionary file user_dict.txt:
平原上的火焰
上 映
In fast mode, each line in the dictionary file contains a custom item + “\t” + frequency (frequency can be omitted; if omitted, the system automatically calculates the frequency to ensure proper segmentation). Note: Blacklist dictionaries are not currently supported (i.e., setting entries like “年” and “末” to achieve segmentation of “年末”). Example dictionary file user_dict.txt:
平原上的火焰 10
Example of loading custom dictionary and output:
>>> from paddlenlp import Taskflow
>>> seg = Taskflow("word_segmentation")
>>> seg("平原上的火焰宣布延期上映")
['平原', '上', '的', '火焰', '宣布', '延期', '上映']
>>> seg = Taskflow("word_segmentation", user_dict="user_dict.txt")
>>> seg("平原上的火焰宣布延期上映")
['平原上的火焰', '宣布', '延期', '上', '映']
Parameter Description#
mode: Specifies the segmentation mode, default is None.
batch_size: Batch size, adjust according to hardware configuration, default is 1.user_dict: Custom dictionary file path, default is None.task_path: Custom task path, default is None.
Part-of-Speech Tagging#
Based on Baidu's Lexical Analysis Tool LAC
Supports Single and Batch Prediction#
>>> from paddlenlp import Taskflow
# Single prediction
>>> tag = Taskflow("pos_tagging")
>>> tag("第十四届全运会在西安举办")
[('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')]
# Batch input, faster average speed
>>> tag(["第十四届全运会在西安举办", "三亚是一个美丽的城市"])
[[('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')], [('三亚', 'LOC'), ('是', 'v'), ('一个', 'm'), ('美丽', 'a'), ('的', 'u'), ('城市', 'n')]]
Custom Dictionary#
You can customize segmentation and POS tagging results by loading a custom dictionary. Each line in the dictionary file represents a custom item, which can be a single word or multiple words. A custom tag can be appended using the format item/tag, with the default model tag n used if no custom tag is specified.
Example dictionary file user_dict.txt:
赛里木湖/LAKE
高/a 山/n
海拔最高
Example of loading custom dictionary and output:
>>> from paddlenlp import Taskflow
>>> tag = Taskflow("pos_tagging")
>>> tag("Sai Li Mu Lake is the highest alpine lake in Xinjiang by elevation")
[('Sai Li Mu Lake', 'LOC'), ('is', 'v'), ('Xinjiang', 'LOC'), ('elevation', 'n'), ('highest', 'a'), ('', 'u'), ('alpine', 'n'), ('lake', 'n')]
>>> my_tag = Taskflow("pos_tagging", user_dict="user_dict.txt")
>>> my_tag("Sai Li Mu Lake is the highest alpine lake in Xinjiang by elevation")
[('Sai Li Mu Lake', 'LAKE'), ('is', 'v'), ('Xinjiang', 'LOC'), ('highest elevation', 'n'), ('', 'u'), ('alpine', 'a'), ('mountain', 'n'), ('lake', 'n')]
Configurable Parameters#
batch_size: Batch size, adjust according to hardware configuration, default 1.user_dict: Custom dictionary file path, default None.task_path: Custom task path, default None.
Named Entity Recognition#
Comprehensive Chinese Entity Tags
Two Supported Modes#
# Precise Mode (default), based on Baidu Jieyu, with 91 built-in part-of-speech and named entity tags
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner")
>>> ner("《Orphan Girl》 is a novel published by Jiuzhou Press in 2010, written by Yu Janyu")
[('《', 'w'), ('Orphan Girl', 'Works_Entity'), ('》', 'w'), ('is', 'Affirmative'), ('2010', 'Time'), ('Jiuzhou Press', 'Organization'), ('publish', 'SceneEvent'), ('', 'Particle'), ('novel', 'Works_Concept'), (',', 'w'), ('author', 'Person_Concept'), ('is', 'Affirmative'), ('Yu Janyu', 'Person_Entity')]
>>> ner = Taskflow("ner", entity_only=True) # Return only entities/concepts
>>> ner("《Orphan Girl》 is a novel published by Jiuzhou Press in 2010, written by Yu Janyu")
[('Orphan Girl', 'Works_Entity'), ('2010', 'Time'), ('Jiuzhou Press', 'Organization'), ('publish', 'SceneEvent'), ('novel', 'Works_Concept'), ('author', 'Person_Concept'), ('Yu Janyu', 'Person_Entity')]
# Fast Mode, based on Baidu LAC, with 24 built-in part-of-speech and named entity tags
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner", mode="fast")
>>> ner("Sanya is a beautiful city")
[('Sanya', 'LOC'), ('is', 'v'), ('a', 'm'), ('beautiful', 'a'), ('', 'u'), ('city', 'n')]
Batch Input for Faster Processing#
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner")
>>> ner(["Hot plum tea is a tea beverage made primarily from plums as the main ingredient", "The Orphan Girl is a novel published by Jiuzhou Publishing House in 2010, written by Yu Jianyu"])
[[('Hot plum tea', 'Food & Drink_Type'), ('is', 'Affirmative'), ('a', 'Quantifier'), ('beverage', 'Food & Drink'), ('made', 'Scene Event'), ('primarily', 'Adverb'), ('from', 'Preposition'), ('plums', 'Food & Drink'), ('as', 'Conjunction'), ('the', 'Determiner'), ('main', 'Adjective'), ('ingredient', 'Object')], [('The Orphan Girl', 'Literary Work_Entity'), ('is', 'Affirmative'), ('a', 'Article'), ('novel', 'Literary Work_Concept'), ('published', 'Scene Event'), ('by', 'Preposition'), ('Jiuzhou Publishing House', 'Organization'), ('in', 'Preposition'), ('2010', 'Time'), (',', 'Punctuation'), ('written', 'Scene Event'), ('by', 'Preposition'), ('Yu Jianyu', 'Person_Entity')]]
Entity Tagging Notes#
Label Set for Precise Mode
Includes 91 POS tags and specific entity categories. The complete label set is as follows:
| WordTag Label Set | ||||||
|---|---|---|---|---|---|---|
| Person_Entity | Organization_Military Organization_Concept | Culture_Institutions/Policies/Agreements | Location_Direction | Term_Medical Terminology | Information_Gender | Negative |
| Person_Concept | Organization_Healthcare Institution | Culture_Surnames & Personal Names | Location_Region | Term_Organism | URL | Quantifier |
| Work_Entity | Organization_Healthcare Institution_Concept | Biology | Location_Region_Country | Disease_Injury | Personality_Trait | Quantifier_Ordinal |
| Work_Concept | Organization_Educational Institution | Biology_Plant | Location_Region_Administrative | Disease_Plant | Sensory_Characteristic | Quantifier_Unit |
| Organization | Organization_Educational Institution_Concept | Biology_Animal | Location_Region_Geographical | Universe | Scene_Event | Interjection |
| Organization_Concept | Object | Brand | Food_Drink | Event | Preposition | Onomatopoeia |
| Organization_Enterprise | Object_Concept | Brand_Type | Food_Dish | Time | Preposition_Directional | Modifier |
| Organization_Enterprise_Concept | Object_Weapon | Place | Food_Beverage | Time_Special Day | Particle | Modifier_Property |
| Organization_Government | Object_Chemical | Place_Concept | Medicine | Time_Dynasty | Pronoun | Modifier_Type |
| Organization_Government_Concept | Other_Roles | Place_Transportation | Medicine_Traditional | Time_Specific | Conjunction | Modifier_Abstract |
| Organization_Sports | Culture | Place_Transportation_Concept | Term | Time_Duration | Adverb | Foreign_Word |
| Organization_Sports_Concept | Culture_Language | Place_Online | Term_Type | Lexicon | Question | Pinyin |
| Organization_Military | Culture_Awards/Events | Place_Online_Concept | Term_Symbol | Information | Affirmative | w (Punctuation) |
Label Set for Fast Mode
| Tag | Meaning | Tag | Meaning | Tag | Meaning | Tag | Meaning |
|---|---|---|---|---|---|---|---|
| n | Noun | f | Directional | s | Locale | t | Time |
| nr | Person | ns | Location | nt | Organization | nw | Work |
| nz | Other Proper | v | Verb | vd | Verb-Adverb | vn | Nominal Verb |
| a | Adjective | ad | Adverbial Adj | an | Nominal Adj | d | Adverb |
| m | Quantifier | q | Measure Word | r | Pronoun | p | Preposition |
| c | Conjunction | u | Particle | xc | Other Function | w | Punctuation |
| PER | Person | LOC | Location | ORG | Organization | TIME | Time |
Custom Dictionary#
You can customize NER results by loading custom dictionaries. Each line in the dictionary file represents a custom item, which can contain one or multiple terms. Terms can be followed by custom labels in the format:
Information Extraction#
DDParser based on the largest Chinese dependency syntax tree library
Supports multiple input formats#
Unsegmented input:
>>> from paddlenlp import Taskflow
>>> ddp = Taskflow("dependency_parsing")
>>> ddp("On February 8, Gu Ailing won the third gold medal at the Beijing Winter Olympics")
[{'word': ['February 8', 'Gu Ailing', 'won', 'Beijing Winter Olympics', 'third gold'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}]
Input using segmentation results:
>>> ddp = Taskflow("dependency_parsing")
>>> ddp.from_segments([['February 8', 'Gu Ailing', 'won', 'Beijing Winter Olympics', 'third gold']])
[{'word': ['February 8', 'Gu Ailing', 'won', 'Beijing Winter Olympics', 'third gold'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}]
Batch input processing for faster average speed#
>>> ddp = Taskflow("dependency_parsing")
>>> ddp(["On February 8, Gu Ailing won the third gold medal at the Beijing Winter Olympics", "She returned to Beijing on the 20th"])
[
{'word': ['February 8', 'Gu Ailing', 'won', 'Beijing Winter Olympics', 'third gold'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']},
{'word': ['She', 'returned to', 'Beijing', 'on the 20th'], 'head': [2, 0, 2, 2], 'deprel': ['SBV', 'HED', 'VOB', 'TMP']}
]
Visualization#
>>> from paddlenlp import Taskflow
>>> ddp = Taskflow("dependency_parsing", return_visual=True)
>>> result = ddp("On February 8, Gu Ailing won the third gold medal at the Beijing Winter Olympics")
# The visualization result is saved as an HTML file in the ~/.paddlenlp/dep_visual/ directory
Configuration Parameters#
batch_size: Batch size, adjust according to hardware configuration, default is 1.tree: Whether to return tree structure, default is False.prob: Whether to return probability values, default is False.use_pos: Whether to use part-of-speech tags, default is False.return_visual: Whether to return visualization results, default is False.link: Visualization style, supports ‘freelayout’ and ‘DDParser’ styles, default is ‘DDParser’.
Multiple Model Choices, Meeting the Needs of Accuracy and Speed#
Using ERNIE 1.0 for prediction:
>>> ddp = Taskflow("dependency_parsing", model="ddparser-ernie-1.0")
>>> ddp("2月8日谷爱凌夺得北京冬奥会第三金")
[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}]
In addition to ERNIE 1.0, ERNIE-Gram pre-trained models can also be used. Among them, model=ddparser (based on LSTM Encoder) is the fastest, while model=ddparser-ernie-gram-zh and model=ddparser-ernie-1.0 offer better performance (with comparable effectiveness between the two).
Output Options#
Output probability values and POS tags:
>>> ddp = Taskflow("dependency_parsing", prob=True, use_pos=True)
>>> ddp("2月8日谷爱凌夺得北京冬奥会第三金")
[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB'], 'postag': ['TIME', 'PER', 'v', 'ORG', 'n'], 'prob': [0.97, 1.0, 1.0, 0.99, 0.99]}]
Dependency relation visualization:
>>> from paddlenlp import Taskflow
>>> ddp = Taskflow("dependency_parsing", return_visual=True)
>>> result = ddp("2月8日谷爱凌夺得北京冬奥会第三金")[0]['visual']
>>> import cv2
>>> cv2.imwrite('test.png', result)

Dependency Parsing Annotation Relation Set#
| Label | Relation Type | Description | Example |
|---|---|---|---|
| SBV | subject-verb | Relationship between subject and predicate | He gave a book (He<--give) |
| VOB | verb-object | Relationship between verb and object | He gave a book (give-->book) |
| POB | prep-object | Relationship between preposition and object | I sold the book (to-->book) |
| ADV | adverbial | Relationship between adverbial and head | I bought a book yesterday (yesterday<--bought) |
| CMP | complement | Relationship between complement and head | I ate it all (eat-->all) |
| ATT | attribute | Relationship between attribute and head | He gave a book (a<--book) |
| F | location | Relationship between locative and head | Playing in the park (park-->in) |
| COO | coordinate | Relationship between coordinate elements | Uncle and aunt (uncle-->aunt) |
| DBL | pivotal | Structure with S-P phrase as object | He invited me to dinner (invite-->me, invite-->dinner) |
| DOB | double-object | Structure with two objects after predicate | He gave me a book (give-->me, give-->book) |
| VV | serial-verb | Relationship between consecutive predicates with same subject | He went out to eat (go out-->eat) |
| IC | independent-clause | Structure with two independent or related clauses | Hello, how to get to the bookstore? (hello<--go) |
| MT | particle | Relationship between particle and head | He gave a book (give-->le) |
| HED | head | The core of the entire sentence |
Configurable Parameters#
batch_size: Batch size, adjust according to the machine configuration, default is 1.model: Select model for the task, options includeddparser,ddparser-ernie-1.0andddparser-ernie-gram-zh.tree: Ensure the output is a well-formed dependency tree, default is True.prob: Whether to output probability values for each arc, default is False.use_pos: Whether to return part-of-speech tags, default is False.use_cuda: Whether to use GPU for tokenization, default is False.return_visual
Information Extraction#
Open-domain General Information Extraction Tool for Multi-scenario Adaptation
Open-domain information extraction is a novel paradigm in information extraction. Its main idea is to minimize human intervention by utilizing a single model to support multiple types of open extraction tasks. Users can employ natural language to define extraction targets and extract information fragments from input texts without predefined entity or relationship categories.
Entity Extraction#
Named Entity Recognition (NER) refers to identifying entities with specific meanings in texts. In open-domain information extraction, the categories of extraction are unrestricted, allowing users to define their own.
For example, if the target entity types are “Time”, “Player”, and “Event Name”, the schema is constructed as follows:
['Time', 'Player', 'Event Name']
Usage example:
>>> from pprint import pprint >>> from paddlenlp import Taskflow >>> schema = ['Time', 'Player', 'Event Name'] # Define the schema for entity extraction >>> ie = Taskflow('information_extraction', schema=schema) >>> pprint(ie("On the morning of February 8, during the Beijing Winter Olympics freestyle skiing women's big air final, Chinese athlete Gu Ailing won the gold medal with 188.25 points!")) # Better print results using pprint [{'Time': [{'end': 27, 'probability': 0.9857378532924486, 'start': 0, 'text': 'On the morning of February 8'}], 'Event Name': [{'end': 87, 'probability': 0.8503089953268272, 'start': 28, 'text': 'Beijing Winter Olympics freestyle skiing women's big air final'}], 'Player': [{'end': 109, 'probability': 0.8981548639781138, 'start': 92, 'text': 'Gu Ailing'}]}]
For example, if the target entity types are “Tumor Size”, “Tumor Count”, “Liver Cancer Grade”, and “Lymphovascular Invasion Grade”, the schema is constructed as follows:
['Tumor Size', 'Tumor Count', 'Liver Cancer Grade', 'Lymphovascular Invasion Grade']
In the previous example, we instantiated a
Taskflowobject. Here, we can reset extraction targets using theset_schemamethod.Usage example:
>>> schema = ['Tumor size', 'Tumor count', 'Liver cancer grade', 'MVI classification']
>>> ie.set_schema(schema)
>>> pprint(ie("(Right hepatic tumor) Hepatocellular carcinoma (Grade II-III, trabecular and pseudoglandular patterns), incomplete tumor capsule, adjacent to hepatic capsule, invading surrounding liver tissue, no evidence of microvascular invasion (MVI classification: M0) or satellite lesions. (1 tumor, size 4.2×4.0×2.8cm)."))
[{'Liver cancer grade': [{'end': 20,
'probability': 0.9243267447402701,
'start': 13,
'text': 'Grade II-III'}],
'Tumor count': [{'end': 84,
'probability': 0.7538413804059623,
'start': 82,
'text': '1 tumor'}],
'Tumor size': [{'end': 100,
'probability': 0.8341128043459491,
'start': 87,
'text': '4.2×4.0×2.8cm'}],
'MVI classification': [{'end': 70,
'probability': 0.9083292325934664,
'start': 67,
'text': 'M0'}]}]
```
- For example, if the target entity types to extract are "person" and "organization", construct the schema as follows:
```text
['person', 'organization']
```
English model invocation example:
```python
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> schema = ['Person', 'Organization']
>>> ie_en = Taskflow('information_extraction', schema=schema, model='uie-base-en')
>>> pprint(ie_en('In 1997, Steve was excited to become the CEO of Apple.'))
[{'Organization': [{'end': 53,
'probability': 0.9985840259877357,
'start': 48,
'text': 'Apple'}],
'Person': [{'end': 14,
'probability': 0.999631971804547,
'start': 9,
'text': 'Steve'}]}]
```
#### Relation Extraction
Relation Extraction (RE) refers to identifying entities from text and extracting semantic relationships between entities to obtain triplet information, i.e., <subject, predicate, object>.
- For example, using "competition name" as the extraction subject, the relationship types to extract include "organizer", "host", and "number of times held". The schema is constructed as follows:
```text
{
'competition name': [
'organizer',
'host',
'number of times held'
]
}
```
Example invocation:
```python
>>> schema = {'Competition Name': ['Organizer', 'Host', 'Number of Editions']} # Define the schema for relation extraction
>>> ie.set_schema(schema) # Reset schema
>>> pprint(ie('The 2022 Language and Intelligence Technology Competition is jointly organized by the Chinese Information Processing Society of China and the China Computer Federation, hosted by Baidu, the Evaluation Working Committee of the Chinese Information Processing Society of China and the Natural Language Processing Committee of the China Computer Federation. It has been held for 4 consecutive editions, becoming one of the most popular Chinese NLP competitions globally.'))
[{'Competition Name': [{'end': 13,
'probability': 0.7825402622754041,
'relations': {'Organizer': [{'end': 22,
'probability': 0.8421710521379353,
'start': 14,
'text': 'Chinese Information Processing Society of China'},
{'end': 30,
'probability': 0.7580801847701935,
'start': 23,
'text': 'China Computer Federation'}],
'Number of Editions': [{'end': 82,
'probability': 0.4671295049136148,
'start': 80,
'text': '4 editions'}],
'Host': [{'end': 39,
'probability': 0.8292706618236352,
'start': 35,
'text': 'Baidu'},
{'end': 72,
'probability': 0.6193477885474685,
'start': 56,
'text': 'Natural Language Processing Committee of the China Computer Federation'},
{'end': 55,
'probability': 0.7000497331473241,
'start': 40,
'text': 'Evaluation Working Committee of the Chinese Information Processing Society of China'}]},
'start': 0,
'text': '2022 Language and Intelligence Technology Competition'}]}]
```
- For example, using "person" as the extraction subject and relationship types "Company" and "Position", the schema is constructed as:
```text
{
'Person': [
'Company',
'Position'
]
}
```
Example of calling the English model:
```python
>>> schema = [{'Person': ['Company', 'Position']}]
>>> ie_en.set_schema(schema)
>>> pprint(ie_en('In 1997, Steve was excited to become the CEO of Apple.'))
[{'Person': [{'end': 14,
'probability': 0.999631971804547,
'relations': {'Company': [{'end': 53,
'probability': 0.9960158209451642,
'start': 48,
'text': 'Apple'}],
'Position': [{'end': 44,
'probability': 0.8871063806420736,
'start': 41,
'text': 'CEO'}]},
'start': 9,
'text': 'Steve'}]}]
```
#### Event Extraction
Event Extraction (EE) refers to the extraction of predefined event triggers and arguments from natural language texts, combining them into structured event information.
- For example, if the extraction target is information such as "seismic intensity", "time", "epicenter location", and "focal depth" for an "earthquake" event, the schema is constructed as:
```text
{
'地震触发词': [
'地震强度',
'时间',
'震中位置',
'震源深度'
]
}
```
The trigger format is unified as `触发词` or `XX 触发词`, where `XX` represents the specific event type. In the above example, the event type is `地震` (earthquake), so the corresponding trigger is `地震触发词`.
Example of calling:
```python
>>> schema = [{'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']}]
>>> ie_en.set_schema(schema)
>>> pprint(ie_en('A magnitude 6.5 earthquake occurred in California at 10:00 AM, with a focal depth of 10 kilometers.'))
```
```python
>>> schema = {'Earthquake trigger words': ['Magnitude', 'Time', 'Epicenter location', 'Focal depth']} # Define the schema for event extraction
>>> ie.set_schema(schema) # Reset schema
>>> ie('Official determination by China Earthquake Networks: A magnitude 3.5 earthquake occurred on May 16 at 06:08 in Fengqing County, Lincang City, Yunnan Province (24.34°N, 99.98°E), with a focal depth of 10 kilometers.')
[{'Earthquake trigger words': [{'text': 'earthquake', 'start': 56, 'end': 58, 'probability': 0.9987181623528585, 'relations': {'Magnitude': [{'text': '3.5 magnitude', 'start': 52, 'end': 56, 'probability': 0.9962985320905915}], 'Time': [{'text': 'May 16, 06:08', 'start': 11, 'end': 22, 'probability': 0.9882578028575182}], 'Epicenter location': [{'text': 'Fengqing County, Lincang City, Yunnan Province (24.34°N, 99.98°E)', 'start': 23, 'end': 50, 'probability': 0.8551415716584501}], 'Focal depth': [{'text': '10 kilometers', 'start': 63, 'end': 67, 'probability': 0.999158304648045}]}}]}]
The English model does not currently support event extraction in zero-shot mode. If you have English event extraction data, please train a custom model.
Sentiment Classification#
Sentence-level sentiment classification, i.e., determining whether the sentiment tendency of a sentence is “positive” or “negative”. The schema is constructed as follows:
'Sentiment classification [positive, negative]'
Usage example:
>>> schema = 'Sentiment classification [positive, negative]' # Define the schema for sentence-level sentiment classification >>> ie.set_schema(schema) # Reset schema >>> ie('This product works really smoothly, I like it very much') [{'Sentiment classification [positive, negative]': [{'text': 'positive', 'probability': 0.9988661643929895}]}]
The schema for English models is constructed as follows:
'Sentiment classification [positive, negative]'
English model usage example:
>>> schema = 'Sentiment classification [positive, negative]' >>> ie_en.set_schema(schema) >>> ie_en("The service is excellent and worth recommending.") [{'Sentiment classification [positive, negative]': [{'text': 'positive', 'probability': 0.9992123579383153}]}]
>>> schema = 'Sentiment classification [negative, positive]'
>>> ie_en.set_schema(schema)
>>> ie_en('I am sorry but this is the worst film I have ever seen in my life.')
[{'Sentiment classification [negative, positive]': [{'text': 'negative', 'probability': 0.9998415771287057}]}]
```
#### Cross-Task Extraction
- For example, simultaneously performing entity extraction and relation extraction in legal scenarios. The schema can be constructed as follows:
```text
[
"Court",
{
"Plaintiff": "Authorized Agent"
},
{
"Defendant": "Authorized Agent"
}
]
```
Calling example:
```
```python
>>> schema = ['court', {'plaintiff': 'attorney'}, {'defendant': 'attorney'}]
>>> ie.set_schema(schema)
>>> pprint(ie("Beijing Haidian District People's Court\nCivil Judgment\n(199x) Jian Chu Zi No. xxx\nPlaintiff: Zhang San.\nAttorney Li Si, Beijing A Law Firm Lawyer.\nDefendant: B Company, Legal Representative Wang Wu, Development Company General Manager.\nAttorney Zhao Liu, Beijing C Law Firm Lawyer."))
[{'plaintiff': [{'end': 37,
'probability': 0.9949814024296764,
'relations': {'attorney': [{'end': 46,
'probability': 0.7956844697990384,
'start': 44,
'text': 'Li Si'}]},
'start': 35,
'text': 'Zhang San'}],
'court': [{'end': 10,
'probability': 0.9221074192336651,
'start': 0,
'text': "Beijing Haidian District People's Court"}],
'defendant': [{'end': 67,
'probability': 0.8437349536631089,
'relations': {'attorney': [{'end': 92,
'probability': 0.7267121388225029,
'start': 90,
'text': 'Zhao Liu'}]},
'start': 64,
'text': 'B Company'}]}]
Model Selection#
Multiple model options to meet accuracy and speed requirements
| Model | Architecture | Language |
|---|---|---|
uie-base (default) |
12-layers, 768-hidden, 12-heads | Chinese |
uie-base-en |
12-layers, 768-hidden, 12-heads | English |
uie-medical-base |
12-layers, 768-hidden, 12-heads | Chinese |
uie-medium |
6-layers, 768-hidden, 12-heads | Chinese |
uie-mini |
6-layers, 384-hidden, 12-heads | Chinese |
uie-micro |
4-layers, 384-hidden, 12-heads | Chinese |
uie-nano |
4-layers, 312-hidden, 12-heads | Chinese |
uie-m-large |
24-layers, 1024-hidden, 16-heads | Chinese/English |
uie-m-base |
12-layers, 768-hidden, 12-heads | Chinese/English |
Example usage of
uie-nano:>>> from paddlenlp import Taskflow >>> schema = ['时间', '选手', '赛事名称'] >>> ie = Taskflow('information_extraction', schema=schema, model="uie-nano") >>> ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!") [{'时间': [{'text': '2月8日上午', 'start': 0, 'end': 6, 'probability': 0.6513581678349247}], '选手': [{'text': '谷爱凌', 'start': 28, 'end': 31, 'probability': 0.9819330659468051}], '赛事名称': [{'text': '北京冬奥会自由式滑雪女子大跳台决赛', 'start': 6, 'end': 23, 'probability': 0.4908131110420939}]}]
uie-m-baseanduie-m-largesupport Chinese-English mixed information extraction. Example usage:
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> schema = ['Time', 'Player', 'Competition', 'Score']
>>> ie = Taskflow('information_extraction', schema=schema, model="uie-m-base", schema_lang="en")
>>> pprint(ie(["2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!", "Rafael Nadal wins French Open Final!"]))
[{'Competition': [{'end': 23,
'probability': 0.9373889907291257,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'Player': [{'end': 31,
'probability': 0.6981119555336441,
'start': 28,
'text': '谷爱凌'}],
'Score': [{'end': 39,
'probability': 0.9888507878270296,
'start': 32,
'text': '188.25分'}],
'Time': [{'end': 6,
'probability': 0.9784080036931151,
'start': 0,
'text': '2月8日上午'}]},
{'Competition': [{'end': 35,
'probability': 0.9851549932171295,
'start': 18,
'text': 'French Open Final'}],
'Player': [{'end': 12,
'probability': 0.9379371275888104,
'start': 0,
'text': 'Rafael Nadal'}]}]
Custom Training#
For simple extraction targets, you can directly use paddlenlp.Taskflow
We conducted experiments on self-built test sets across three vertical domains: internet, healthcare, and finance:
<table>
<tr><th row_span='2'><th colspan='2'>Finance<th colspan='2'>Healthcare<th colspan='2'>Internet
<tr><td><th>0-shot<th>5-shot<th>0-shot<th>5-shot<th>0-shot<th>5-shot
<tr><td>uie-base (12L768H)<td>46.43<td>70.92<td><b>71.83</b><td>85.72<td>78.33<td>81.86
<tr><td>uie-medium (6L768H)<td>41.11<td>64.53<td>65.40<td>75.72<td>78.32<td>79.68
<tr><td>uie-mini (6L384H)<td>37.04<td>64.65<td>60.50<td>78.36<td>72.09<td>76.38
<tr><td>uie-micro (4L384H)<td>37.53<td>62.11<td>57.04<td>75.92<td>66.00<td>70.22
<tr><td>uie-nano (4L312H)<td>38.94<td>66.83<td>48.29<td>76.74<td>62.86<td>72.35
<tr><td>uie-m-large (24L1024H)<td><b>49.35</b><td><b>74.55</b><td>70.50<td><b>92.66</b><td><b>78.49</b><td><b>83.02</b>
<tr><td>uie-m-base (12L768H)<td>38.46<td>74.31<td>63.37<td>87.32<td>76.27<td>80.13
</table>
0-shot indicates no training data, directly through ```paddlenlp.Taskflow```
```When making predictions, 5-shot means each category contains 5 labeled data points for fine-tuning the model. **Experiments show that UIE can further improve performance in vertical scenarios with few-shot data**.
#### Configurable Parameter Descriptions
* `schema`: Defines the task extraction target. Refer to the out-of-the-box examples for different tasks.
* `schema_lang`: Sets the language of the schema, defaults to `zh`, options include `zh` and `en`. As Chinese and English schemas are constructed differently, the schema language must be specified. This parameter only applies to `uie-m-base` and `uie-m-large` models.
* `batch_size`: Batch size. Adjust according to hardware, defaults to 1.
* `model`: Select model for the task, defaults to `uie-base`. Options: `uie-base`, `uie-medium`, `uie-mini`, `uie-micro`, `uie-nano`, `uie-medical-base`, `uie-base-en`.
* `position_prob`: The model's probability (0~1) for span start/end positions. Results below this threshold are filtered, defaults to 0.5. The final span probability is the product of start and end position probabilities.
* `precision`: Select model precision, defaults to `fp32`, options: `fp16` and `fp32`. `fp16` provides faster inference. If choosing `fp16`, ensure the machine has correct NVIDIA drivers and software with **CUDA ≥11.2, cuDNN ≥8.1.1**. First-time use requires installing dependencies (mainly **ensure onnxruntime-gpu is installed**). Also, ensure GPU CUDA Compute Capability >7.0, typical devices include V100, T4, A10, A100, GTX 20/30 series. For CUDA Compute Capability and precision support, see NVIDIA docs: [GPU Hardware and Precision Support Matrix](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-840-ea/support-matrix/index.html#hardware-precision-matrix).
</div></details>
### Jieyu Knowledge Annotation
<details><summary> Knowledge annotation tool covering all Chinese vocabulary</summary><div>
#### Part-of-Speech Knowledge Annotation
>>> from paddlenlp import Taskflow
>>> wordtag = Taskflow("knowledge_mining")
>>> wordtag("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
[{'text': '《孤女》是2010年九州出版社出版的小说,作者是余兼羽', 'items': [{'item': '《', 'offset': 0, 'wordtag_label': 'w', 'length': 1}, {'item': '孤女', 'offset': 1, 'wordtag_label': '作品类_实体', 'length': 2}, {'item': '》', 'offset': 3, 'wordtag_label': 'w', 'length': 1}, {'item': '是', 'offset': 4, 'wordtag_label': '肯定词', 'length': 1, 'termid': '肯定否定词_cb_是'}, {'item': '2010年', 'offset': 5, 'wordtag_label': '时间类', 'length': 5, 'termid': '时间阶段_cb_2010年'}, {'item': '九州出版社', 'offset': 10, 'wordtag_label': '组织机构类', 'length': 5, 'termid': '组织机构_eb_九州出版社'}, {'item': '出版', 'offset': 15, 'wordtag_label': '场景事件', 'length': 2, 'termid': '场景事件_cb_出版'}, {'item': '的', 'offset': 17, 'wordtag_label': '助词', 'length': 1, 'termid': '助词_cb_的'}, {'item': '小说', 'offset': 18, 'wordtag_label': '作品类_概念', 'length': 2, 'termid': '小说_cb_小说'}, {'item': ',', 'offset': 20, 'wordtag_label': 'w', 'length': 1}, {'item': '作者', 'offset': 21, 'wordtag_label': '人物类_概念', 'length': 2, 'termid': '人物_cb_作者'}, {'item': '是', 'offset': 23, 'wordtag_label': '肯定词', 'length': 1, 'termid': '肯定否定词_cb_是'}, {'item': '余兼羽', 'offset': 24, 'wordtag_label': '人物类_实体', 'length': 3}]}]
Configurable Parameters Description:
batch_size: Batch size, adjust according to hardware specifications, default is 1.linking: Enable word class-based linking, default is True.task_path: Custom task path, default is None.user_dict: User-defined dictionary file, default is None.
The knowledge mining - word class annotation task contains 91 part-of-speech and proper noun category labels. The complete label set is shown in the following table:
| WordTag Label Set | ||||||
|---|---|---|---|---|---|---|
| Person_Entity | Organization_MilitaryOrganization_Concept | Culture_SystemPolicyAgreement | LocationDirection | Term_MedicalTerm | Information_Gender | Negation |
| Person_Concept | Organization_MedicalHealth | Culture_SurnamePersonName | Location_WorldRegion | Term_Organism | URL | Quantifier |
| Work_Entity | Organization_MedicalHealth_Concept | Biology | Location_Country | DiseaseInjury | PersonalityTrait | Quantifier_Ordinal |
| Work_Concept | Organization_Education | Biology_Plant | Location_Administrative | Disease_PlantPest | SensoryTrait | Quantifier_Unit |
| Organization | Organization_Education_Concept | Biology_Animal | Location_Geographical | Universe | SceneEvent | Interjection |
| Organization_Concept | Object | Brand | Food | Event | Preposition | Onomatopoeia |
| Organization_Enterprise | Object_Concept | Brand_Type | Food_Dish | Time | Preposition_Directional | Modifier |
| Organization_Enterprise_Concept | Object_Weapon | Place | Food_Beverage | Time_SpecialDay | Particle | Modifier_Property |
| Organization_Government | Object_Chemical | Place_Concept | Medicine | Time_Dynasty | Pronoun | Modifier_Type |
| Organization_Government_Concept | OtherRole | Place_Transportation | Medicine_Traditional | Time_ExactTime | Conjunction | Modifier_Chem |
| Organization_Sports | Culture | Place_Transportation_Concept | Term | Time_Duration | Adverb | ForeignWord |
| Organization_Sports_Concept | Culture_Language | Place_Online | Term_Type | Vocabulary | Question | Pinyin |
| Organization_Military | Culture_AwardEvent | Place_Online_Concept | Term_Symbol | Information | Affirmation | w (Punctuation) |
Knowledge Template Information Extraction#
```python
>>> from paddlenlp import Taskflow
>>> wordtag_ie = Taskflow("knowledge_mining", with_ie=True)
>>> wordtag_ie('《忘了所有》是一首由王杰作词、作曲并演唱的歌曲,收录在专辑同名《忘了所有》中,由波丽佳音唱片于1996年08月31日发行。')
[[{'text': '《Forgot All》 is a song composed and performed by Wang Jie, included in the eponymous album 《Forgot All》, released by Polydor Records on August 31, 1996.', 'items': [{'item': '《', 'offset': 0, 'wordtag_label': 'w', 'length': 1}, {'item': 'Forgot All', 'offset': 1, 'wordtag_label': 'works_entity', 'length': 4}, {'item': '》', 'offset': 5, 'wordtag_label': 'w', 'length': 1}, {'item': 'is', 'offset': 6, 'wordtag_label': 'affirmative', 'length': 1}, {'item': 'a', 'offset': 7, 'wordtag_label': 'quantifier_unit', 'length': 2}, {'item': 'by', 'offset': 9, 'wordtag_label': 'preposition', 'length': 1}, {'item': 'Wang Jie', 'offset': 10, 'wordtag_label': 'person_entity', 'length': 2}, {'item': 'compose lyrics', 'offset': 12, 'wordtag_label': 'scene_event', 'length': 2}, {'item': '、', 'offset': 14, 'wordtag_label': 'w', 'length': 1}, {'item': 'compose music', 'offset': 15, 'wordtag_label': 'scene_event', 'length': 2}, {'item': 'and', 'offset': 17, 'wordtag_label': 'conjunction', 'length': 1}, {'item': 'perform', 'offset': 18, 'wordtag_label': 'scene_event', 'length': 2}, {'item': 'the', 'offset': 20, 'wordtag_label': 'particle', 'length': 1}, {'item': 'song', 'offset': 21, 'wordtag_label': 'works_concept', 'length': 2}, {'item': ',', 'offset': 23, 'wordtag_label': 'w', 'length': 1}, {'item': 'included', 'offset': 24, 'wordtag_label': 'scene_event', 'length': 2}, {'item': 'in', 'offset': 26, 'wordtag_label': 'preposition', 'length': 1}, {'item': 'the album', 'offset': 27, 'wordtag_label': 'works_concept', 'length': 2}, {'item': 'eponymous', 'offset': 29, 'wordtag_label': 'scene_event', 'length': 2}, {'item': '《', 'offset': 31, 'wordtag_label': 'w', 'length': 1}, {'item': 'Forgot All', 'offset': 32, 'wordtag_label': 'works_entity', 'length': 4}, {'item': '》', 'offset': 36, 'wordtag_label': 'w', 'length': 1}, {'item': 'in', 'offset': 37, 'wordtag_label': 'vocabulary', 'length': 1}, {'item': ',', 'offset': 38, 'wordtag_label': 'w', 'length': 1}, {'item': 'by', 'offset': 39, 'wordtag_label': 'preposition', 'length': 1}, {'item': 'Polydor Records', 'offset': 40, 'wordtag_label': 'person_entity', 'length': 4}, {'item': 'released', 'offset': 44, 'wordtag_label': 'works_concept', 'length': 2}, {'item': 'on', 'offset': 46, 'wordtag_label': 'preposition', 'length': 1}, {'item': 'August 31, 1996', 'offset': 47, 'wordtag_label': 'time_specific', 'length': 11}, {'item': 'release', 'offset': 58, 'wordtag_label': 'scene_event', 'length': 2}, {'item': '。', 'offset': 60, 'wordtag_label': 'w', 'length': 1}]}], [[{'HEAD_ROLE': {'item': 'Wang Jie', 'offset': 10, 'type': 'person_entity'}, 'TAIL_ROLE': [{'item': 'Forgot All', 'type': 'works_entity', 'offset': 1}], 'GROUP': 'creation', 'TRIG': [{'item': 'compose lyrics', 'offset': 12}, {'item': 'compose music', 'offset': 15}, {'item': 'perform', 'offset': 18}], 'SRC': 'REVERSE'}, {'HEAD_ROLE': {'item': 'Forgot All', 'type': 'works_entity', 'offset': 1}, 'TAIL_ROLE': [{'item': 'Wang Jie', 'offset': 10, 'type': 'person_entity'}], 'GROUP': 'creator', 'SRC': 'HTG', 'TRIG': [{'item': 'compose lyrics', 'offset': 12}, {'item': 'compose music', 'offset': 15}, {'item': 'perform', 'offset': 18}]}, {'HEAD_ROLE': {'item': 'Forgot All', 'type': 'works_entity', 'offset': 1}, 'TAIL_ROLE': [{'item': 'song', 'offset': 21, 'type': 'works_concept'}], 'GROUP': 'type', 'SRC': 'TAIL'}, {'HEAD_ROLE': {'item': 'Forgot All', 'offset': 32, 'type': 'works_entity'}, 'TAIL_ROLE': [{'item': 'Forgot All', 'type': 'works_entity', 'offset': 1}], 'GROUP': 'included', 'TRIG': [{'item': 'included', 'offset': 24}], 'SRC': 'REVERSE'}, {'HEAD_ROLE': {'item': 'Forgot All', 'type': 'works_entity', 'offset': 1}, 'TAIL_ROLE': [{'item': 'Forgot All', 'offset': 32, 'type': 'works_entity'}], 'GROUP': 'included_in', 'SRC': 'HGT', 'TRIG': [{'item': 'included', 'offset': 24}]}, {'HEAD_ROLE': {'item': 'Forgot All', 'offset': 32, 'type': 'works_entity'}, 'TAIL_ROLE': [{'item': 'Wang Jie', 'type': 'person_entity', 'offset': 10}], 'GROUP': 'creator', 'TRIG': [{'item': 'the album', 'offset': 27}], 'SRC': 'REVERSE'}, {'HEAD_ROLE': {'item': 'Wang Jie', 'type': 'person_entity', 'offset': 10}, 'TAIL_ROLE': [{'item': 'Forgot All', 'offset': 32, 'type': 'works_entity'}], 'GROUP': 'creation', 'SRC': 'HGT', 'TRIG': [{'item': 'the album', 'offset': 27}]}, {'HEAD_ROLE': {'item': 'Forgot All', 'type': 'works_entity', 'offset': 32}, 'TAIL_ROLE': [{'item': 'released', 'offset': 44, 'type': 'works_concept'}], 'GROUP': 'type', 'SRC': 'TAIL'}]]]```
**Custom Extraction Schema**
```python
>>> from pprint import pprint
>>> schema = [
{
"head_role": "Work_Entity",
"group": "Creator",
"tail_role": [
{
"main": [
"Person_Entity"
],
"support": []
}
],
"trig_word": [
"Lyricist",
],
"trig_type": "trigger",
"reverse": False,
"trig_direction": "B",
"rel_group": "Creation"
}]
>>> wordtag_ie.set_schema(schema)
>>> pprint(wordtag_ie('《忘了所有》是一首由王杰作词、作曲并演唱的歌曲,收录在专辑同名《忘了所有》中,由波丽佳音唱片于1996年08月31日发行。')[1])
[[{'GROUP': 'Creation',
'HEAD_ROLE': {'item': '王杰', 'offset': 10, 'type': 'Person_Entity'},
'SRC': 'REVERSE',
'TAIL_ROLE': [{'item': '忘了所有', 'offset': 1, 'type': 'Work_Entity'}],
'TRIG': [{'item': '作词', 'offset': 12}]},
{'GROUP': 'Creator',
'HEAD_ROLE': {'item': '忘了所有', 'offset': 1, 'type': 'Work_Entity'},
'SRC': 'HTG',
'TAIL_ROLE': [{'item': '王杰', 'offset': 10, 'type': 'Person_Entity'}],
'TRIG': [{'item': '作词', 'offset': 12}]}]]
For detailed explanation of WordTag-IE’s information extraction capabilities, please refer to WordTag-IE Documentation.
Noun Phrase Annotation#
```python
>>> from paddlenlp import Taskflow
>>> nptag = Taskflow("knowledge_mining", model="nptag")
>>> nptag("Sweet and Sour Spare Ribs")
[{'text': 'Sweet and Sour Spare Ribs', 'label': 'Dish'}]
>>> nptag(["Sweet and Sour Spare Ribs", "Monascus purpureus"])
[{'text': 'Sweet and Sour Spare Ribs', 'label': 'Dish'}, {'text': 'Monascus purpureus', 'label': 'Microorganism'}]
# Use `linking` to output coarse-grained category labels `category`, i.e., vocabulary labels from WordTag.
>>> nptag = Taskflow("knowledge_mining", model="nptag", linking=True)
>>> nptag(["Sweet and Sour Spare Ribs", "Monascus purpureus"])
[{'text': 'Sweet and Sour Spare Ribs', 'label': 'Dish', 'category': 'Food Category_Dish'}, {'text': 'Monascus purpureus', 'label': 'Microorganism', 'category': 'Biology Category_Microorganism'}]
Configurable Parameter Descriptions:
batch_size: Batch size, adjust according to hardware configuration, default is 1.max_seq_len: Maximum sequence length, default is 64.linking: Enable linking with WordTag category labels, default is False.task_path: Custom task path, default is None.
Text Correction#
End-to-End Text Correction Model with Pinyin Features: ERNIE-CSC
Support Single and Batch Prediction#
>>> from paddlenlp import Taskflow
>>> corrector = Taskflow("text_correction")
# Single input
>>> corrector('When facing adversity, we must confront it courageously and become more resilient.')
[{'source': 'When facing adversity, we must confront it courageously and become more resilient.', 'target': 'When facing adversity, we must confront it courageously and become more resilient.', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]
# Batch prediction
>>> corrector(['When facing adversity, we must confront it courageously and become more resilient.', 'Life is like this; it is through challenges that we grow stronger and become more optimistic.'])
[{'source': 'When facing adversity, we must confront it courageously and become more resilient.', 'target': 'When facing adversity, we must confront it courageously and become more resilient.', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}, {'source': 'Life is like this; it is through challenges that we grow stronger and become more optimistic.', 'target': 'Life is like this; it is through challenges that we grow stronger and become more optimistic.', 'errors': [{'position': 18, 'correction': {'拙': '茁'}}]}]
#### Configurable Parameters
* `batch_size`: Batch size, adjust according to the machine configuration, default is 1.
* `task_path`: Custom task path, default is None.
</div></details>
### Text Similarity
<details><summary> Trained on million-scale Dureader Retrieval dataset with RocketQA to achieve state-of-the-art text similarity</summary><div>
#### Single Input
+ Query-Query similarity matching
```python
>>> from paddlenlp import Taskflow
>>> similarity = Taskflow("text_similarity")
>>> similarity([["Spring is suitable for planting what flowers?", "Spring is suitable for planting what vegetables?"]])
[{'text1': 'Spring is suitable for planting what flowers?', 'text2': 'Spring is suitable for planting what vegetables?', 'similarity': 0.83402544}]
Query-Passage similarity matching
>>> similarity = Taskflow("text_similarity", model='rocketqa-base-cross-encoder')
>>> similarity([["How many days are national statutory holidays?", "Current statutory holidays are 1 day for New Year's Day, 3 days for Spring Festival, 1 day for Qingming Festival, 1 day for May Day, 1 day for Dragon Boat Festival, 3 days for National Day, 1 day for Mid-Autumn Festival, totaling 11 days. Statutory rest days include 52 weekends per year with 104 days total. Combined total is 115 days."]])
[{'text1': 'How many days are national statutory holidays?', 'text2': 'Current statutory holidays are 1 day for New Year's Day, 3 days for Spring Festival, 1 day for Qingming Festival, 1 day for May Day, 1 day for Dragon Boat Festival, 3 days for National Day, 1 day for Mid-Autumn Festival, totaling 11 days. Statutory rest days include 52 weekends per year with 104 days total. Combined total is 115 days.', 'similarity': 0.7174624800682068}]
Batch Input with Faster Average Speed#
Query-Query similarity matching
>>> from paddlenlp import Taskflow
>>> similarity = Taskflow("text_similarity")
>>> similarity([[['What flowers are suitable for planting in spring?','What vegetables are suitable for planting in spring?'],['Who has the HD version of Kurumi?','Who has this HD image?']]])
[{'text1': 'What flowers are suitable for planting in spring?', 'text2': 'What vegetables are suitable for planting in spring?', 'similarity': 0.83402544}, {'text1': 'Who has the HD version of Kurumi?', 'text2': 'Who has this HD image?', 'similarity': 0.6540646}]
Query-Passage similarity matching
>>> similarity = Taskflow("text_similarity", model='rocketqa-base-cross-encoder')
>>> similarity([["How many national statutory holidays are there in total?", "Currently, statutory holidays include 1 day for New Year's Day, 3 days for Spring Festival, 1 day for Qingming Festival, 1 day for May Day, 1 day for Dragon Boat Festival, 3 days for National Day, 1 day for Mid-Autumn Festival, totaling 11 days. Statutory rest days include 52 weekends per year, amounting to 104 days. Combined, there are 115 days in total."],["What factors determine the pricing of alcoholic beverages?", "There are many factors that determine the pricing of alcoholic beverages: the pedigree of the beverage (i.e., place of origin, production techniques, etc.); aging time, etc. Alcoholic beverages are a product that's difficult to standardize - as long as you dare to set a price and there are buyers willing to pay, it's considered worth that value."]])
[{'text1': 'How many national statutory holidays are there in total?', 'text2': 'Currently, statutory holidays include 1 day for New Year's Day, 3 days for Spring Festival, 1 day for Qingming Festival, 1 day for May Day, 1 day for Dragon Boat Festival, 3 days for National Day, 1 day for Mid-Autumn Festival, totaling 11 days. Statutory rest days include 52 weekends per year, amounting to 104 days. Combined, there are 115 days in total.', 'similarity': 0.7174624800682068}, {'text1': 'What factors determine the pricing of alcoholic beverages?', 'text2': 'There are many factors that determine the pricing of alcoholic beverages: the pedigree of the beverage (i.e., place of origin, production techniques, etc.); aging time, etc. Alcoholic beverages are a product that's difficult to standardize - as long as you dare to set a price and there are buyers willing to pay, it's considered worth that value.', 'similarity': 0.9069755673408508}]
Model Selection#
Multiple model options to meet accuracy and speed requirements
| Model | Architecture | Language |
|---|---|---|
rocketqa-zh-dureader-cross-encoder |
12-layers, 768-hidden, 12-heads | Chinese |
simbert-base-chinese (Default) |
12-layers, 768-hidden, 12-heads | Chinese |
rocketqa-base-cross-encoder |
12-layers, 768-hidden, 12-heads | Chinese |
rocketqa-medium-cross-encoder |
6-layers, 768-hidden, 12-heads | Chinese |
rocketqa-mini-cross-encoder |
6-layers, 384-hidden, 12-heads | Chinese |
rocketqa-micro-cross-encoder |
4-layers, 384-hidden, 12-heads | Chinese |
rocketqa-nano-cross-encoder |
4-layers, 312-hidden, 12-heads | Chinese |
rocketqav2-en-marco-cross-encoder |
12-layers, 768-hidden, 12-heads | English |
Configurable Parameters#
batch_size: Batch size; adjust according to machine configuration, default is 1.max_seq_len: Maximum sequence length, default is 384.task_path: Custom task path, default is None.
Sentiment Analysis#
Integrates BiLSTM, SKEP, UIE models, supporting comment dimension analysis, opinion extraction, sentiment classification and other sentiment analysis tasks
Supports different models with two modes: fast speed and high accuracy#
pip install --upgrade paddle-pipelines
# Command line examples
paddle-pipelines sentiment_analysis --input "The product is good" --model rocketqa-nano-cross-encoder --schema ["Baidu", "Tencent"]
>>> from paddlenlp import Taskflow
# Default uses the bilstm model for prediction, which is fast
>>> senta = Taskflow("sentiment_analysis")
>>> senta("这个产品用起来真的很流畅,我非常喜欢")
[{'text': '这个产品用起来真的很流畅,我非常喜欢', 'label': 'positive', 'score': 0.9938690066337585}]
# Use the SKEP sentiment analysis pre-trained model for prediction, which has high accuracy
>>> senta = Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch")
>>> senta("作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。")
[{'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。', 'label': 'positive', 'score': 0.984320878982544}]
# Use the UIE model for sentiment analysis, which has strong sample transfer capability
# 1. Sentence-level sentiment analysis
>>> schema = ['sentiment[positive, negative]']
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta('蛋糕味道不错,店家服务也很好')
[{'sentiment[positive, negative]': [{'text': 'positive', 'probability': 0.996646058824652}]}]
# 2. Aspect-level sentiment analysis
>>> # Aspect Term Extraction
>>> # schema = ["evaluation aspect"]
>>> # Aspect - Opinion Extraction
>>> # schema = [{"evaluation aspect":["opinion terms"]}]
>>> # Aspect - Sentiment Extraction
>>> # schema = [{"evaluation aspect":["sentiment[positive, negative, not mentioned]"]}]
>>> # Aspect - Sentiment - Opinion Extraction
>>> schema = [{"evaluation aspect":["opinion terms", "sentiment[positive, negative, not mentioned]"]}]
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta('蛋糕味道不错,店家服务也很热情')
[{'evaluation aspect': [{'text': '服务', 'start': 9, 'end': 11, 'probability': 0.9709093024793489, 'relations': { 'opinion terms': [{'text': '热情', 'start': 13, 'end': 15, 'probability': 0.9897222206316556}], 'sentiment[positive, negative, not mentioned]': [{'text': 'positive', 'probability': 0.9999327669598301}]}}, {'text': '味道', 'start': 2, 'end': 4, 'probability': 0.9105472387838915, 'relations': {'opinion terms': [{'text': '不错', 'start': 4, 'end': 6, 'probability': 0.9946981266891619}], 'sentiment[positive, negative, not mentioned]': [{'text': 'positive', 'probability': 0.9998829392709467}]}}]}]
Batch Input for Faster Average Speed#
>>> from paddlenlp import Taskflow
>>> schema = [{"Evaluation Aspect":["Opinion Word", "Sentiment Orientation[Positive, Negative, Not Mentioned]"]}]
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta(["The room is small but clean", "The owner's service is warm and the price is affordable"])
[{'Evaluation Aspect': [{'text': 'room', 'start': 0, 'end': 2, 'probability': 0.998526653966298, 'relations': {'Opinion Word': [{'text': 'clean', 'start': 6, 'end': 8, 'probability': 0.9899580841973474}, {'text': 'small', 'start': 2, 'end': 4, 'probability': 0.9945525066163512}], 'Sentiment Orientation[Positive, Negative, Not Mentioned]': [{'text': 'Positive', 'probability': 0.6077412795680956}]}}]}, {'Evaluation Aspect': [{'text': 'service', 'start': 2, 'end': 4, 'probability': 0.9913965811617516, 'relations': {'Opinion Word': [{'text': 'warm', 'start': 4, 'end': 6, 'probability': 0.9995530034336753}], 'Sentiment Orientation[Positive, Negative, Not Mentioned]': [{'text': 'Positive', 'probability': 0.9956709542206106}]}}, {'text': 'price', 'start': 7, 'end': 9, 'probability': 0.9970075537913772, 'relations': {'Opinion Word': [{'text': 'affordable', 'start': 10, 'end': 12, 'probability': 0.9991568497876635}], 'Sentiment Orientation[Positive, Negative, Not Mentioned]': [{'text': 'Positive', 'probability': 0.9943191048602245}]}}]}]
Configurable Parameters Description#
batch_size: Batch size, adjust according to hardware configuration, default is 1.model: Model selection for the task, available options includebilstm,skep_ernie_1.0_large_ch,uie-senta-base,uie-senta-medium,uie-senta-mini,uie-senta-micro,uie-senta-nano.task_path: Custom task path, default is None.
Generative Q&A#
Using the Largest Chinese Open-Source CPM Model for Q&A
Supports Single and Batch Prediction#
```python
>>> from paddlenlp import Taskflow
>>> qa = Taskflow("question_answering")
# Single input
>>> qa("What is the land area of China?")
[{'text': 'What is the land area of China?', 'answer': '9.6 million square kilometers.'}]
# Multiple inputs
>>> qa(["What is the land area of China?", "Where is the capital of China?"])
[{'text': 'What is the land area of China?', 'answer': '9.6 million square kilometers.'}, {'text': 'Where is the capital of China?', 'answer': 'Beijing.'}]
Configurable Parameters#
batch_size: Batch size, adjust according to hardware configuration, default is 1.
Poetry Generation#
Using the largest Chinese open-source CPM model for poetry generation
Supports single and batch prediction#
>>> from paddlenlp import Taskflow
>>> poetry = Taskflow("poetry_generation")
# Single input
>>> poetry("Dense woods, no sight of people")
[{'text': 'Dense woods, no sight of people', 'answer': ', but voices echo.'}]
# Multiple inputs
>>> poetry(["Dense woods, no sight of people", "Raising my cup, I beckon the bright moon"])
[{'text': 'Dense woods, no sight of people', 'answer': ', but voices echo.'}, {'text': 'Raising my cup, I beckon the bright moon', 'answer': ', lowering my head, I miss my hometown.'}]
Configurable Parameters#
batch_size: Batch size, adjust according to hardware configuration, default is 1.
Open-Domain Dialogue#
PLATO-Mini trained on 1B corpus for Chinese casual conversation, supports multi-turn dialogue
Non-interactive Mode#
>>> from paddlenlp import Taskflow
>>> dialogue = Taskflow("dialogue")
>>> dialogue(["Have you eaten?"])
['Just finished, what are you doing?']
>>> dialogue(["Hello", "Have you eaten?"], ["Who are you?"])
['Yes, how about you', 'I'm Li Ming']
Configurable parameters:
batch_size: Batch size, adjust according to hardware configuration, default is 1.max_seq_len: Maximum sequence length, default is 512.
Interactive Mode#
>>> from paddlenlp import Taskflow
>>> dialogue = Taskflow("dialogue")
# Input `exit` to exit interactive mode
>>> dialogue.interactive_mode(max_turn=3)
'''
[Human]: Hello
[Bot]: Hello, nice to meet you. May I ask if you like sports?
[Human]: Yes
[Bot]: What sports do you like?
[Human]: Basketball, do you like basketball?
[Bot]: Of course, I really enjoy playing basketball.
'''
>>> from paddlenlp import Taskflow
# Default model is Salesforce/codegen-350M-mono
>>> codegen = Taskflow("code_generation", model="Salesforce/codegen-2B-mono")
# Single input
>>> codegen("def hello_world():")
['\n print("Hello World")']
# Batch input
>>> codegen(["Get the length of array", "def hello_world():"])
['\n n = len(a)\n\n #', '\n print("Hello World!")']
#### Configurable Parameters
* `model`: Optional model, default is Salesforce/codegen-350M-mono. Supported models refer to [CodeGen Documentation](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/slm/examples/code_generation/codegen/README.md).
* `batch_size`: Batch size, adjust according to hardware, default is 1.
* `max_length`: Maximum length of generated code, default is 128.
* `min_length`: Minimum length of generated code, default is 0.
* `decode_strategy`: Decoding strategy, supports greedy_search, beam_search and sampling, default is sampling.
* `temperature`: Decoding parameter temperature, default is 0.6.
* `top_k`: Decoding parameter top_k, default is 5.
* `top_p`: Decoding parameter top_p, default is 1.0.
* `num_beams`: Beam size for beam_search decoding, default is 4.
* `length_penalty`: Length penalty for decoding, default is 1.0.
* `repetition_penalty`: Repetition penalty for decoding, default is 1.1.
* `output_scores`: Whether to output decoding scores, default is False.
```python
>>> from paddlenlp import Taskflow
>>> summarizer = Taskflow("text_summarization")
# Single input
>>> summarizer('In 2022, the Chinese real estate industry entered a transition period of growing pains. The traditional "high leverage, fast turnover" model became unsustainable. Vanke even publicly declared that the Chinese real estate market has entered the "Black Iron Age".')
# Output: ['Vanke declares Chinese real estate has entered the "Black Iron Age"']
# Multiple inputs
>>> summarizer([
'According to reports, in 2022 the Ministry of Education will focus on three key themes: "consolidate and improve, deepen implementation, and innovate breakthroughs". The goal is to further strengthen schools as the main front of education, continue to prioritize the "double reduction" policy as the most important task, and focus on four areas to continuously consolidate and improve the "double reduction" efforts: enhancing homework design quality, improving after-school services, elevating classroom teaching standards, and promoting balanced development.',
'Codonopsis pilosula has lipid-lowering and blood pressure-reducing effects. It can thoroughly remove blood waste, providing stable preventive benefits for patients with coronary heart disease and cardiovascular diseases. Regular consumption of Codonopsis can help prevent the risks of the "three highs" (hyperlipidemia, hypertension, hyperglycemia). Additionally, Codonopsis has functions of tonifying qi and blood, reducing central nervous system excitation, regulating digestive system functions, and strengthening the spleen and lungs.'
])
# Output: ['Ministry of Education: Will continuously consolidate and improve "double reduction" efforts from four aspects', 'Codonopsis helps reduce risks of the "three highs"']
#### Configurable Parameters
* `model`: Optional model, defaults to `IDEA-CCNL/Randeng-Pegasus-523M-Summary-Chinese`.
* `batch_size`: Batch size, adjust according to hardware capabilities, default 1.
</div></details>
### Document Intelligence
<details><summary>  Powered by ERNIE-Layout, a multilingual cross-modal layout-enhanced document pre-training model </summary><div>
#### Input Format
[ {”doc”: “./invoice.jpg”, “prompt”: [”What is the invoice number?”, “What is the verification code?”]}, {”doc”: “./resume.png”, “prompt”: [”What position does WuBaiDing want to take this time?”, “Where did WuBaiDing attend university?”, “What was the major studied in university?”]} ]
Default OCR uses PaddleOCR, while supporting user-provided OCR results via ``word_boxes``, formatted as ``List[str, List[float, float, float, float]]``.
[ {”doc”: doc_path, “prompt”: prompt, “word_boxes”: word_boxes} ]
#### Support for Single and Batch Prediction
- Supports local image path input
<div align="center">
<img src=https://user-images.githubusercontent.com/40840292/194748579-f9e8aa86-7f65-4827-bfae-824c037228b3.png height=800 hspace='20'/>
</div>
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> docprompt = Taskflow("document_intelligence")
>>> pprint(docprompt([{"doc": "./resume.png", "prompt": ["What position does Wubading want to apply for this time?", "Where did Wubading attend university?", "What was the major studied in university?"]}]))
[{'prompt': 'What position does Wubading want to apply for this time?',
'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': 'Customer Manager'}]},
{'prompt': 'Where did Wubading attend university?',
'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': 'Guangzhou Wubading College'}]},
{'prompt': 'What was the major studied in university?',
'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': 'Finance (Undergraduate)'}]}]
HTTP image URL input

>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> docprompt = Taskflow("document_intelligence")
>>> pprint(docprompt([{"doc": "https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg", "prompt": ["What is the invoice number?", "What is the verification code?"]}]))
[{'prompt': 'What is the invoice number?',
'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]},
{'prompt': 'What is the verification code?',
'result': [{'end': 233,
'prob': 1.0,
'start': 231,
'value': '01107 555427109891646'}]}]
Configurable Parameters#
batch_size: Batch size. Adjust according to your machine configuration, default is 1.lang: Select language for PaddleOCR. Usechfor mixed Chinese-English images,enworks better for English images, default isch.topn: If the model detects multiple results, returns the top n highest probability results, default is 1.
Question Generation#
Based on Baidu's self-developed Chinese pre-trained model UNIMO-Text and large-scale multi-domain question generation dataset
Supports single and batch prediction#
>>> from paddlenlp import Taskflow
# Default model: unimo-text-1.0-dureader_qg
>>> question_generator = Taskflow("question_generation")
# Single input
>>> question_generator([
{"context": "奇峰黄山千米以上的山峰有77座,整座黄山就是一座花岗岩的峰林,自古有36大峰,36小峰,最高峰莲花峰、最险峰天都峰和观日出的最佳点光明顶构成黄山的三大主峰。", "answer": "莲花峰"}
])
'''
['What is the highest peak in Huangshan']
'''
# Multiple inputs
>>> question_generator([
{"context": "奇峰黄山千米以上的山峰有77座,整座黄山就是一座花岗岩的峰林,自古有36大峰,36小峰,最高峰莲花峰、最险峰天都峰和观日出的最佳点光明顶构成黄山的三大主峰。", "answer": "莲花峰"},
{"context": "弗朗索瓦·韦达外文名:franciscusvieta国籍:法国出生地:普瓦图出生日期:1540年逝世日期:1603年12月13日职业:数学家主要成就:为近代数学的发展奠定了基础。", "answer": "法国"}
])
'''
['What is the highest peak in Huangshan', 'Where was François born']
'''
Configurable Parameters Description#
model: Optional model, default is unimo-text-1.0-dureader_qg, supported models include [”unimo-text-1.0”, “unimo-text-1.0-dureader_qg”, “unimo-text-1.0-question-generation”, “unimo-text-1.0-question-generation-dureader_qg”].device: Running device, default is “gpu”.template: Template, options include [0, 1, 2, 3], where 1 indicates using the default template, 0 indicates no template.batch_size: Batch size, adjust according to hardware configuration, default is 1.output_scores: Whether to output decoding scores, default is False.is_select_from_num_return_sequences: Whether to select the optimal sequence from multiple returned sequences. When True, if num_return_sequences is not 1, automatically selects the sequence with the highest decoding score as the final result; otherwise returns num_return_sequences sequences, default is True.max_length: Maximum length of generated text, default is 50.min_length: Minimum length of generated text, default is 3.decode_strategy: Decoding strategy, supports beam_search and sampling, default is beam_search.temperature: Decoding parameter temperature, default is 1.0.top_k: Decoding parameter top_k, default is 0.top_p: Decoding parameter top_p, default is 1.0.num_beams: Decoding parameter num_beams, represents the beam size for beam_search decoding, default is 6.num_beam_groups: Decoding parameter num_beam_groups, default is 1.diversity_rate: Decoding parameter diversity_rate, default is 0.0.length_penalty: Decoding length penalty value, default is 1.2.num_return_sequences: Number of decoding return sequences, default is 1.repetition_penalty: Decoding repetition penalty value, default is 1.use_fast: Indicates whether to enable high-performance prediction based on FastGeneration. Note that FastGeneration’s high-performance prediction only supports GPU, default is False.use_fp16_decoding: Indicates whether to use fp16 for prediction when high-performance prediction is enabled. If not used, fp32 will be used, default is False.
Zero-Shot Text Classification#
Zero-Shot General Text Classification Tool for Multiple Scenarios
The main idea of general text classification is to use a single model to support various “generic classification” tasks including general classification, sentiment analysis, semantic similarity calculation, textual entailment, and multi-choice reading comprehension. Users can define arbitrary label combinations for text classification without domain restrictions or prompt settings.
Sentiment Analysis#
```python
#### Sentiment Analysis
```python
>>> cls = Taskflow("zero_shot_text_classification", schema=["This is a positive review", "This is a negative review"])
>>> cls("The room is clean and bright, very nice")
[{'predictions': [{'label': 'This is a positive review', 'score': 0.9072999699439914}], 'text_a': 'The room is clean and bright, very nice'}]
>>> cls("The product is acceptable, but the delivery was very slow. Won't buy from this store again.")
[{'predictions': [{'label': 'This is a negative review', 'score': 0.9282672873429476}], 'text_a': 'The product is acceptable, but the delivery was very slow. Won't buy from this store again.'}]
Intent Recognition#
>>> from paddlenlp import Taskflow
>>> schema = ["Disease diagnosis", "Treatment plan", "Etiology analysis", "Indicator interpretation", "Medical advice", "Disease description", "Prognosis description", "Precautions", "Efficacy evaluation", "Medical expenses"]
>>> cls("Where to treat congenital pachyonychia?")
[{'predictions': [{'label': 'Medical advice', 'score': 0.5494891306403806}], 'text_a': 'Where to treat congenital pachyonychia?'}]
>>> cls("What causes lower abdominal pain in males?")
[{'predictions': [{'label': 'Etiology analysis', 'score': 0.5763229815300723}], 'text_a': 'What causes lower abdominal pain in males?'}]
Semantic Similarity Calculation#
>>> from paddlenlp import Taskflow
>>> cls = Taskflow("zero_shot_text_classification", schema=["Different", "Same"])
>>> cls([["How to view contract", "Where can I see the contract"]])
[{'predictions': [{'label': 'Same', 'score': 0.9951385264364382}], 'text_a': 'How to view contract', 'text_b': 'Where can I see the contract'}]
>>> cls([["Why no confirmation call for loan information", "Why did I receive a customer service call after repayment"]])
[{'predictions': [{'label': 'Different', 'score': 0.9991497973466908}], 'text_a': 'Why no confirmation call for loan information', 'text_b': 'Why did I receive a customer service call after repayment'}]
Entailment Inference#
>>> from paddlenlp import Taskflow
>>> cls = Taskflow("zero_shot_text_classification", schema=["irrelevant", "entailment", "contradiction"])
>>> cls([["A cyclist is riding along a city street towards a tower with a clock.", "The cyclist is heading towards the clock tower."]])
[{'predictions': [{'label': 'entailment', 'score': 0.9931122738524856}], 'text_a': 'A cyclist is riding along a city street towards a tower with a clock.', 'text_b': 'The cyclist is heading towards the clock tower.'}]
>>> cls([["A weirdo with long hair and beard wearing a brightly colored shirt in the subway.", "The shirt is new."]])
[{'predictions': [{'label': 'irrelevant', 'score': 0.997680189334587}], 'text_a': 'A weirdo with long hair and beard wearing a brightly colored shirt in the subway.', 'text_b': 'The shirt is new.'}]
>>> cls([["A mother in green shirt and a man in all-black clothes are dancing.", "Both are wearing white pants."]])
[{'predictions': [{'label': 'contradiction', 'score': 0.9666946163628479}], 'text_a': 'A mother in green shirt and a man in all-black clothes are dancing.', 'text_b': 'Both are wearing white pants.'}]
#### Configurable Parameters Description
* `batch_size`: Batch size, please adjust according to your machine configuration, default is 1.
* `task_path`: Custom task path, default is None.
* `schema`: Define the candidate set of task labels.
* `model`: Select model for the task, default is `utc-base`, supports `utc-xbase`, `utc-base`, `utc-medium`, `utc-micro`, `utc-mini`, `utc-nano`, `utc-pico`.
* `max_seq_len`: Maximum input sequence length, including all labels, default is 512.
* `pred_threshold`: Model's prediction probability for labels ranges from 0 to 1. Results below this threshold will be filtered out, default is 0.5.
* `precision`: Select model precision, default is `fp32`, options include `fp16` and `fp32`. `fp16` provides faster inference speed. If choosing `fp16`, please ensure:
1. The machine has proper NVIDIA drivers and software installed **with CUDA >= 11.2, cuDNN >= 8.1.1**. First-time users need to install dependencies as prompted.
2. The GPU's CUDA Compute Capability must be >7.0. Typical supported devices include V100, T4, A10, A100, GTX 20-series and 30-series GPUs. For details about CUDA Compute Capability and precision support, refer to NVIDIA documentation: [GPU Hardware and Precision Support Matrix](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-840-ea/support-matrix/index.html#hardware-precision-matrix).
</div></details>
### Model Feature Extraction
<details><summary>  Based on Baidu's self-developed Chinese cross-modal pretraining model ERNIE-ViL 2.0</summary><div>
#### Multimodal Feature Extraction
from paddlenlp import Taskflow from PIL import Image import paddle.nn.functional as F vision_language = Taskflow(”feature_extraction”)
Single input#
image_embeds = vision_language(Image.open(”demo/000000039769.jpg”)) image_embeds[”features”] Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[-0.59475428, -0.69795364, 0.22144008, 0.88066685, -0.58184201,
Single input#
text_embeds = vision_language(”A photo of a cat”) text_embeds[’features’] Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[ 0.04250504, -0.41429776, 0.26163983, 0.29910022, 0.39019185, -0.41884750, -0.19893740, 0.44328332, 0.08186490, 0.10953025, ……
Multiple inputs#
image_embeds = vision_language([Image.open(”demo/000000039769.jpg”)]) image_embeds[”features”] Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[-0.59475428, -0.69795364, 0.22144008, 0.88066685, -0.58184201, ……
Multiple inputs#
text_embeds = vision_language([”A photo of a cat”, “A photo of a dog”]) text_embeds[”features”] Tensor(shape=[2, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[ 0.04250504, -0.41429776, 0.26163983, …, 0.26221892, 0.34387422, 0.18779707], [ 0.06672225, -0.41456309, 0.13787819, …, 0.21791610, 0.36693242, 0.34208565]])
image_features = image_embeds[”features”] text_features = text_embeds[”features”] image_features /= image_features.norm(axis=-1, keepdim=True) text_features /= text_features.norm(axis=-1, keepdim=True) logits_per_image = 100 * image_features @ text_features.t() probs = F.softmax(logits_per_image, axis=-1) probs Tensor(shape=[1, 2], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[0.99833173, 0.00166824]])
Model Selection#
Multiple model options to meet accuracy and speed requirements
| Model | Vision | Text | Language |
|---|---|---|---|
PaddlePaddle/ernie_vil-2.0-base-zh (default) |
ViT | ERNIE | Chinese |
OFA-Sys/chinese-clip-vit-base-patch16 |
ViT-B/16 | RoBERTa-wwm-Base | Chinese |
OFA-Sys/chinese-clip-vit-large-patch14 |
ViT-L/14 | RoBERTa-wwm-Base | Chinese |
OFA-Sys/chinese-clip-vit-large-patch14-336px |
ViT-L/14 | RoBERTa-wwm-Base | Chinese |
Configurable Parameters Description#
batch_size: Batch size, please adjust according to the machine’s configuration, default is 1._static_mode: Static graph mode, enabled by default.model: Select the model for the task, defaults toPaddlePaddle/ernie_vil-2.0-base-zh.
Text Feature Extraction#
```python
>>> from paddlenlp import Taskflow
>>> import paddle.nn.functional as F
>>> text_encoder = Taskflow("feature_extraction", model='rocketqa-zh-base-query-encoder')
>>> text_embeds = text_encoder(['What flowers are suitable to plant in spring?', 'Who has the high-resolution image of this character?'])
>>> text_features1 = text_embeds["features"]
>>> text_features1
Tensor(shape=[2, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.27640465, -0.13405125, 0.00612330, ..., -0.15600294,
-0.18932408, -0.03029604],
[-0.12041329, -0.07424965, 0.07895312, ..., -0.17068857,
0.04485796, -0.18887770]])
>>> text_embeds = text_encoder('What vegetables are suitable to plant in spring?')
>>> text_features2 = text_embeds["features"]
>>> text_features2
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.32578075, -0.02398480, -0.18929179, -0.18639392, -0.04062131,
......
>>> probs = F.cosine_similarity(text_features1, text_features2)
>>> probs
Tensor(shape=[2], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[0.86455142, 0.41222256])
Model Selection#
Multiple model options to meet accuracy and speed requirements
| Model | Layers | Dimension | Language |
|---|---|---|---|
rocketqa-zh-dureader-query-encoder |
12 | 768 | Chinese |
rocketqa-zh-dureader-para-encoder |
12 | 768 | Chinese |
rocketqa-zh-base-query-encoder |
12 | 768 | Chinese |
rocketqa-zh-base-para-encoder |
12 | 768 | Chinese |
moka-ai/m3e-base |
12 | 768 | Chinese |
rocketqa-zh-medium-query-encoder |
6 | 768 | Chinese |
rocketqa-zh-medium-para-encoder |
6 | 768 | Chinese |
rocketqa-zh-mini-query-encoder |
6 | 384 | Chinese |
rocketqa-zh-mini-para-encoder |
6 | 384 | Chinese |
rocketqa-zh-micro-query-encoder |
4 | 384 | Chinese |
rocketqa-zh-micro-para-encoder |
4 | 384 | Chinese |
rocketqa-zh-nano-query-encoder |
4 | 312 | Chinese |
rocketqa-zh-nano-para-encoder |
4 | 312 | Chinese |
rocketqav2-en-marco-query-encoder |
12 | 768 | English |
rocketqav2-en-marco-para-encoder |
12 | 768 | English |
ernie-search-base-dual-encoder-marco-en" |
12 | 768 | English |
Configurable Parameters#
batch_size: Batch size, adjust according to hardware configuration, default is 1max_seq_len: Maximum sequence length of text, default is 128return_tensors: Return type, options: pd and np, default is pdmodel: Model selection for the task, default isPaddlePaddle/ernie_vil-2.0-base-zhpooling_mode: Pooling strategy for sentence embeddings, options: ‘max_tokens’, ‘mean_tokens’, ‘mean_sqrt_len_tokens’, ‘cls_token’, default is ‘cls_token’ (formoka-ai/m3e-base)
PART II Customized Training#
Supported Task List
For specific business datasets, you can further optimize model performance. Supported tasks for customized training:
| Task Name | Default Path | |
|---|---|---|
Taskflow("word_segmentation", mode="base") |
$HOME/.paddlenlp/taskflow/lac |
Example |
Taskflow("word_segmentation", mode="accurate") |
$HOME/.paddlenlp/taskflow/wordtag |
Example |
Taskflow("pos_tagging") |
$HOME/.paddlenlp/taskflow/lac |
Example |
Taskflow("ner", mode="fast") |
$HOME/.paddlenlp/taskflow/lac |
Example |
Taskflow("ner", mode="accurate") |
$HOME/.paddlenlp/taskflow/wordtag |
Example |
Taskflow("information_extraction", model="uie-base") |
$HOME/.paddlenlp/taskflow/information_extraction/uie-base |
Example |
Taskflow("information_extraction", model="uie-tiny") |
$HOME/.paddlenlp/taskflow/information_extraction/uie-tiny |
Example |
Taskflow("dependency_parsing", model="ddparser") |
$HOME/.paddlenlp/taskflow/dependency_parsing/ddparser |
Example |
Taskflow("dependency_parsing", model="ddparser-ernie-1.0") |
$HOME/.paddlenlp/taskflow/dependency_parsing/ddparser-ernie-1.0 |
Example |
Taskflow("dependency_parsing", model="ddparser-ernie-gram-zh") |
$HOME/.paddlenlp/taskflow/dependency_parsing/ddparser-ernie-gram-zh |
Example |
Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch") |
$HOME/.paddlenlp/taskflow/sentiment_analysis/skep_ernie_1.0_large_ch |
Example |
Taskflow("knowledge_mining", model="wordtag") |
$HOME/.paddlenlp/taskflow/wordtag |
Example |
Taskflow("knowledge_mining", model="nptag") |
$HOME/.paddlenlp/taskflow/knowledge_mining/nptag |
Example |
Taskflow("zero_shot_text_classification", model="utc-base") |
$HOME/.paddlenlp/taskflow/zero_shot_text_classification/utc-base |
Example |
Customized Training Example
Here we demonstrate how to customize your own model using the named entity recognition Taskflow("ner", mode="accurate") as an example.
After calling the Taskflow interface, the program automatically downloads relevant files to $HOME/.paddlenlp/taskflow/wordtag/. This default path contains the following files:
You are a professional NLP technical translator. Translate Chinese to English while:
1. Preserving EXACT formatting (markdown/rst/code)
2. Keeping technical terms in English
3. Maintaining code/math blocks unchanged
4. Using proper academic grammar
5. Keep code block in documents original
6. Keep the link in markdown/rst the same. E.g. [link](#here) remains [link](#here), do not localize anchor names
7. Keep html tags in markdown/rst unchanged
8. Return only translation result without additional messages
```text
$HOME/.paddlenlp/taskflow/wordtag/
├── model_state.pdparams # Default model parameter file
├── model_config.json # Default model configuration file
└── tags.txt # Default tag file
Refer to the corresponding example to prepare the dataset and tag file
tags.txt. Execute the corresponding training script to obtain your ownmodel_state.pdparamsandmodel_config.json.Modify the tag file
tags.txtaccording to your dataset.Save the above files to any custom path. The files in the custom path should be consistent with those in the default path:
custom_task_path/
├── model_state.pdparams # Custom model parameter file
├── model_config.json # Custom model configuration file
└── tags.txt # Custom tag file
Specify the custom path via
task_pathand load the custom model using Taskflow for one-click prediction:
from paddlenlp import Taskflow
my_ner = Taskflow("ner", mode="accurate", task_path="./custom_task_path/")
Model Algorithms#
| Task Name | Model | Model Details | Training Set |
| Chinese Word Segmentation | Default Mode: BiGRU+CRF | Training Details | Baidu's self-built dataset, containing ~22M sentences covering multiple scenarios |
| Fast Mode: Jieba | - | - | |
| Accurate Mode: WordTag | Training Details | Baidu's self-built dataset with term system based on TermTree | |
| Part-of-Speech Tagging | BiGRU+CRF | Training Details | Baidu's self-built dataset containing 22M sentences covering multiple scenarios |
| Named Entity Recognition | Accurate Mode: WordTag | Training Details | Baidu's self-built dataset with term system based on TermTree |
| Fast Mode: BiGRU+CRF | Training Details | Baidu's self-built dataset containing 22M sentences covering multiple scenarios | |
| Dependency Parsing | DDParser | Training Details | Baidu's self-built dataset, DuCTB 1.0 Chinese Dependency Treebank |
| Information Extraction | UIE | Training Details | Baidu's self-built dataset |
| Term Knowledge Annotation | Term Knowledge Annotation: WordTag | Training Details | Baidu's self-built dataset with term system based on TermTree |
| Noun Phrase Annotation: NPTag | Training Details | Baidu's self-built dataset | |
| Text Similarity | SimBERT | - | 22M pairs of similar sentences from Baidu Knows |
| Sentiment Analysis | BiLSTM | - | Baidu's self-built dataset |
| SKEP | Training Details | Baidu's self-built dataset | |
| UIE | Training Details | Baidu's self-built dataset | |
| Generative QA | CPM | - | 100GB-scale Chinese data |
| Intelligent Poetry | CPM | - | 100GB-scale Chinese data |
| Open-Domain Dialogue | PLATO-Mini | - | Billion-scale Chinese dialogue data |
| Zero-shot Text Classification | UTC | Training Details | Baidu's self-built dataset |
FAQ#
Q: How to modify the task save path in Taskflow?
A: By default, Taskflow saves task-related files to $HOME/.paddlenlp/taskflow/. You can specify a custom save path in the following ways:
Set the environment variable:
export TASKFLOW_HOME="custom_path"Specify the
task_pathparameter when initializing Taskflow:
my_ner = Taskflow("ner", task_path="./custom_task_path/")
HOME/.paddlenlp. You can customize the save path via the home_path` parameter during task initialization. Example:
from paddlenlp import Taskflow
ner = Taskflow("ner", home_path="/workspace")
By doing so, the ner task-related files will be saved to the /workspace path.
Q: Downloading or calling models failed multiple times. What should I do if downloads keep failing?
A: Taskflow automatically saves task-related models and files to $HOME/.paddlenlp/taskflow. If downloads or calls fail, you can delete the corresponding files in this path and try again.
Q: How to improve prediction speed in Taskflow?
A: You can adjust the batch_size appropriately according to your device specifications and use batch input to improve average speed. Example:
from paddlenlp import Taskflow
# The precise mode model has larger size. Adjust batch_size with your machine specs.
seg_accurate = Taskflow("word_segmentation", mode="accurate", batch_size=32)
# Batch input (list of multiple sentences) for faster prediction
texts = ["Hot plum tea is a tea drink primarily made from plums",
"《Orphan Girl》is a 2010 novel published by Jiuzhou Press, written by Yu Jianyu"]
seg_accurate(texts)
Word segmentation via this approach can significantly improve prediction speed.
Q: Will more tasks be supported in the future?
A: Taskflow will continue to expand supported tasks. We’ll adjust development priorities based on developer feedback.
Comment Opinion Extraction#
Comment opinion extraction refers to extracting evaluation aspects and opinion words from text.
For example, to extract evaluation aspects and their corresponding opinion words and sentiment orientations, the schema is constructed as:
{ 'Evaluation Aspect': [ 'Opinion Word', 'Sentiment Orientation[Positive, Negative]' ] }Example usage:
The English model schema is constructed as follows:
{ 'Aspect': [ 'Opinion', 'Sentiment classification [negative, positive]' ] }Example invocation of the English model: