PaddleNLP Embedding API#
Introduction#
PaddleNLP provides multiple open-source pre-trained word vector models. Users can load corresponding pre-trained models by specifying the model name when using paddlenlp.embeddings.TokenEmbedding. This document details the usage of TokenEmbedding and lists the supported pre-trained embedding models in PaddleNLP.
Usage#
TokenEmbedding Parameters#
| Parameter | Type | Attributes |
|---|---|---|
| embedding_name | string | Name of pre-trained embedding, available through paddlenlp.embeddings.list_embedding_name() or Embedding Model Summary. |
| unknown_token | string | Token representing unknown words. |
| unknown_token_vector | list or np.array | Used to initialize vector for unknown token. Default None (initializes vector with normal distribution). |
| extended_vocab_path | string | File path for extended vocabulary. Vocabulary format: one word per line. |
| trainable | bool | Whether the embedding is trainable. True indicates embedding parameters can be updated, False means frozen. |
Initialization#
from paddlenlp.embeddings import TokenEmbedding
# Initialize with default parameters
word_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# Initialize with extended vocabulary
extended_word_embedding = TokenEmbedding(
embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300",
extended_vocab_path="./custom_vocab.txt",
unknown_token="[UNK]",
unknown_token_vector=[0.]*300)
Querying Embedding Results#
# Get embedding vector for single word
vector = word_embedding.search("natural")
# Get embedding vectors for word list
vectors = word_embedding.search(["natural", "language"])
Visualizing Embedding Results#
# Visualize with PCA
word_embedding.visualize(
words=["apple", "orange", "car", "train"],
output_path="./visualization.png")
Calculating Cosine Similarity of Word Vectors#
similarity = word_embedding.cosine_sim("apple", "orange")
Computing Word Vector Inner Products#
inner_product = word_embedding.dot("apple", "orange")
Training#
# Example training process (requires custom implementation)
word_embedding.train(
corpus_path="./text_corpus.txt",
save_dir="./retrained_embeddings")
Word Segmentation#
# Example word segmentation (requires actual text input)
tokens = word_embedding.tokenize("Natural Language Processing")
Pre-trained Models#
Chinese Word Vectors#
| Model Name | Dimensions | Corpus | Vocabulary Size | Download |
|---|---|---|---|---|
| w2v.baidu_encyclopedia | 300 | Baidu Encyclopedia | 1,238,371 | Link |
English Word Vectors#
| Model Name | Dimensions | Corpus | Vocabulary Size | Download |
|---|---|---|---|---|
| glove.6B | 300 | Wikipedia 2014 | 400,000 | Link |
Word2Vec#
# Word2Vec example usage
word2vec_embedding = TokenEmbedding(embedding_name="word2vec-google-news-300")
GloVe#
# GloVe example usage
glove_embedding = TokenEmbedding(embedding_name="glove.6B.300d")
FastText#
# FastText example usage
fasttext_embedding = TokenEmbedding(embedding_name="fasttext-wiki-news-subwords-300")
Usage#
# Example loading
embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
Model Information#
# Get embedding metadata
print(f"Embedding dimension: {embedding.embedding_dim}")
print(f"Vocabulary size: {embedding.vocab_size}")
Acknowledgements#
We thank the open-source community and researchers for their contributions to NLP resources.
Reference Papers#
Mikolov, T., et al. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv:1301.3781.
Pennington, J., et al. (2014). GloVe: Global Vectors for Word Representation. EMNLP 2014.
Bojanowski, P., et al. (2017). Enriching Word Vectors with Subword Information. arXiv:1607.04606.
import paddle
from paddlenlp.embeddings import TokenEmbedding, list_embedding_name
paddle.set_device("cpu")
# Check pre-trained embedding names:
print(list_embedding_name()) # ['w2v.baidu_encyclopedia.target.word-word.dim300']
# Initialize TokenEmbedding, automatically downloads and loads data if not present
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# View token_embedding details
print(token_embedding)
Object type: <paddlenlp.embeddings.token_embedding.TokenEmbedding object at 0x7fda7eb5f290>
Unknown index: 635963
Unknown token: [UNK]
Padding index: 635964
Padding token: [PAD]
Parameter containing:
Tensor(shape=[635965, 300], dtype=float32, place=CPUPlace, stop_gradient=False,
[[-0.24200200, 0.13931701, 0.07378800, ..., 0.14103900, 0.05592300, -0.08004800],
[-0.08671700, 0.07770800, 0.09515300, ..., 0.11196400, 0.03082200, -0.12893000],
[-0.11436500, 0.12201900, 0.02833000, ..., 0.11068700, 0.03607300, -0.13763499],
...,
[ 0.02628800, -0.00008300, -0.00393500, ..., 0.00654000, 0.00024600, -0.00662600],
[-0.00924490, 0.00652097, 0.01049327, ..., -0.01796000, 0.03498908, -0.02209341],
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ]])
Query embedding results#
test_token_embedding = token_embedding.search("China")
print(test_token_embedding)
[[ 0.260801 0.1047 0.129453 -0.257317 -0.16152 0.19567 -0.074868
0.361168 0.245882 -0.219141 -0.388083 0.235189 0.029316 0.154215
-0.354343 0.017746 0.009028 0.01197 -0.121429 0.096542 0.009255
...,
-0.260592 -0.019668 -0.063312 -0.094939 0.657352 0.247547 -0.161621
0.289043 -0.284084 0.205076 0.059885 0.055871 0.159309 0.062181
0.123634 0.282932 0.140399 -0.076253 -0.087103 0.07262 ]]
Visualizing Embedding Results#
The embedding results can be visualized using the High Dimensional component of deep learning visualization tool VisualDL. Follow these steps:
# Get first 1000 tokens from vocabulary
labels = token_embedding.vocab.to_tokens(list(range(0,1000)))
test_token_embedding = token_embedding.search(labels)
# Import LogWriter from VisualDL
from visualdl import LogWriter
with LogWriter(logdir='./visualize') as writer:
writer.add_embeddings(tag='test', mat=test_token_embedding, metadata=labels)
After execution, a visualize directory will be created containing the logs. Start VisualDL via command line:
visualdl --logdir ./visualize
Open your browser to view the visualization after startup.
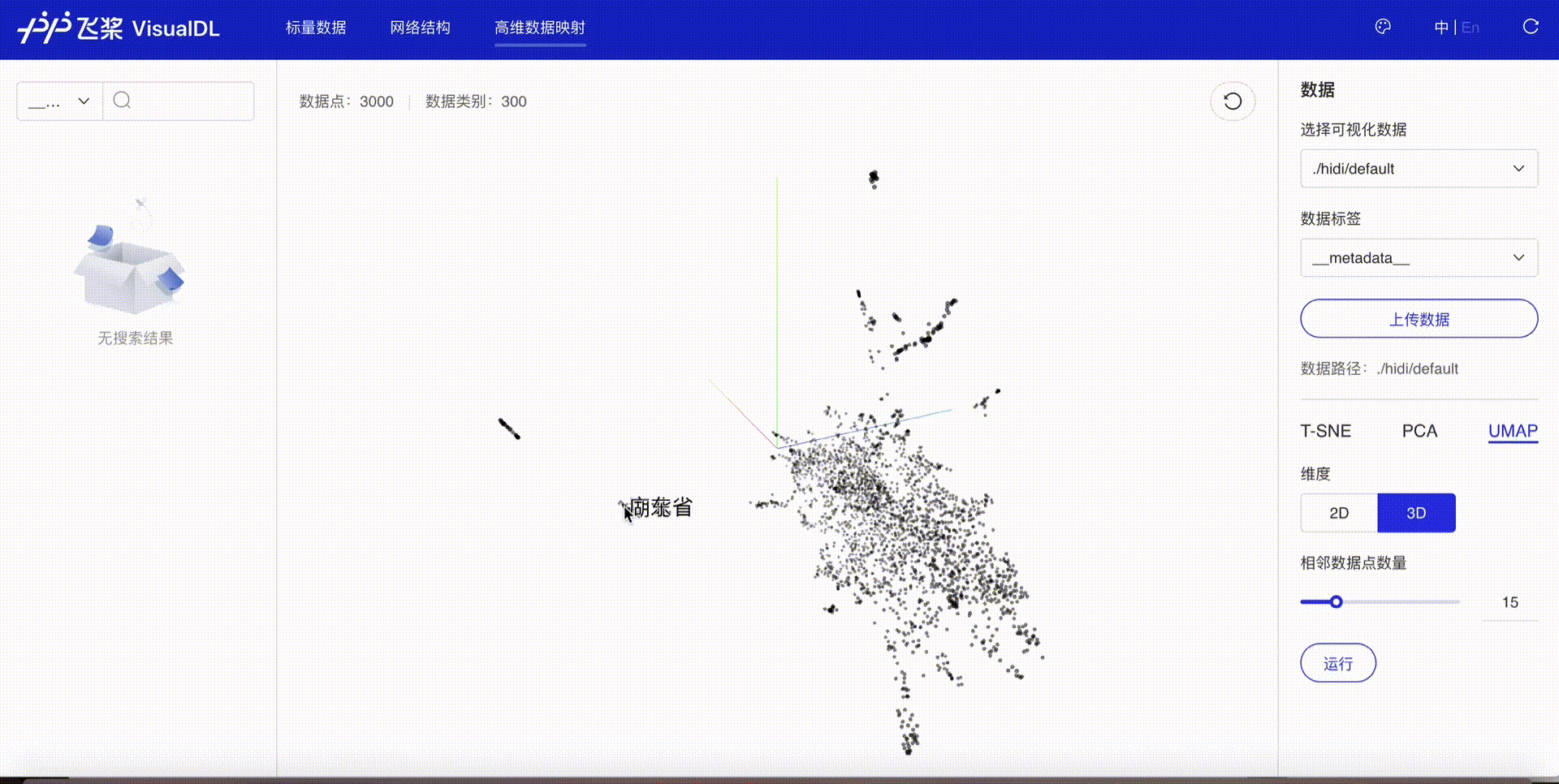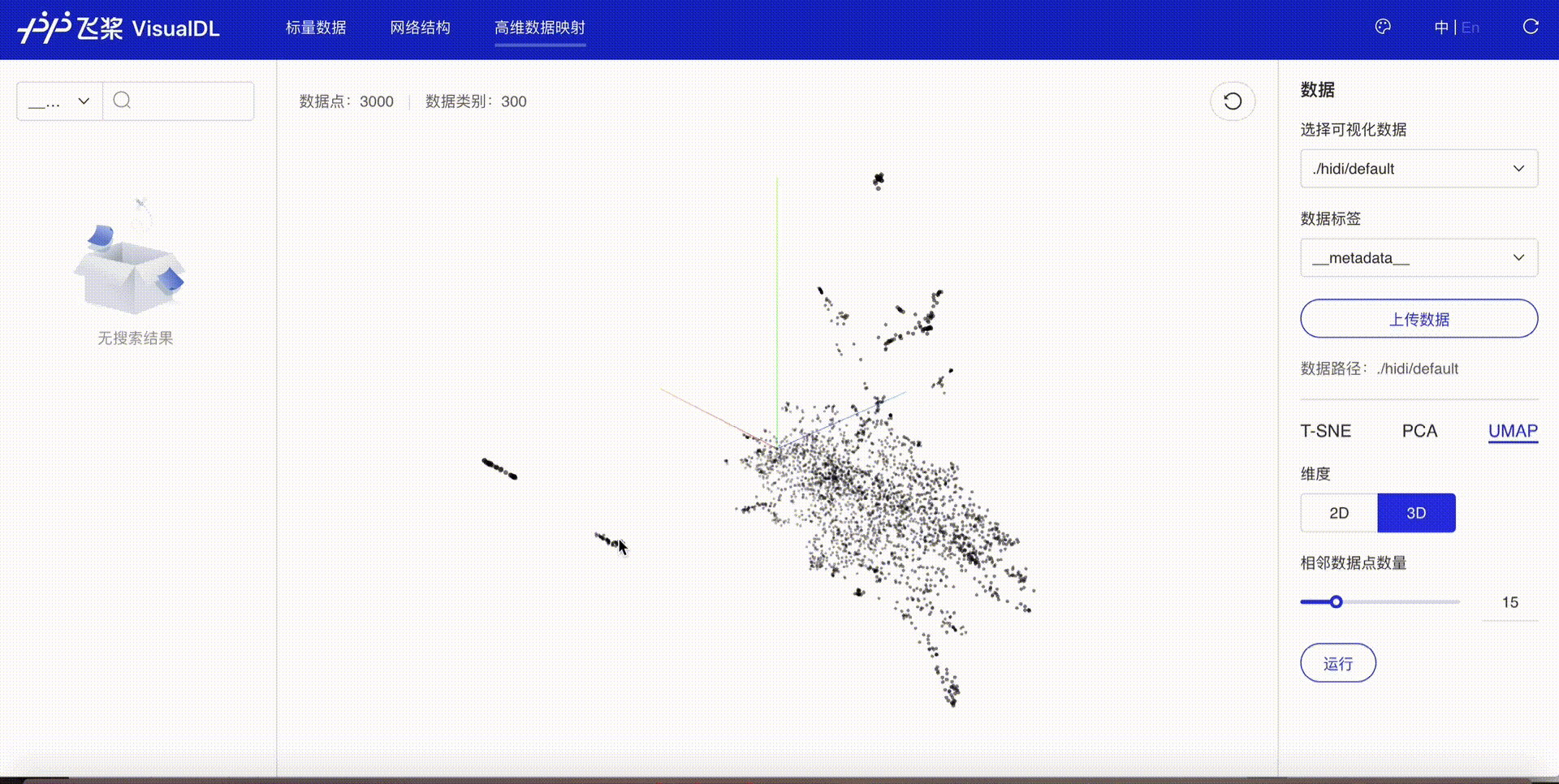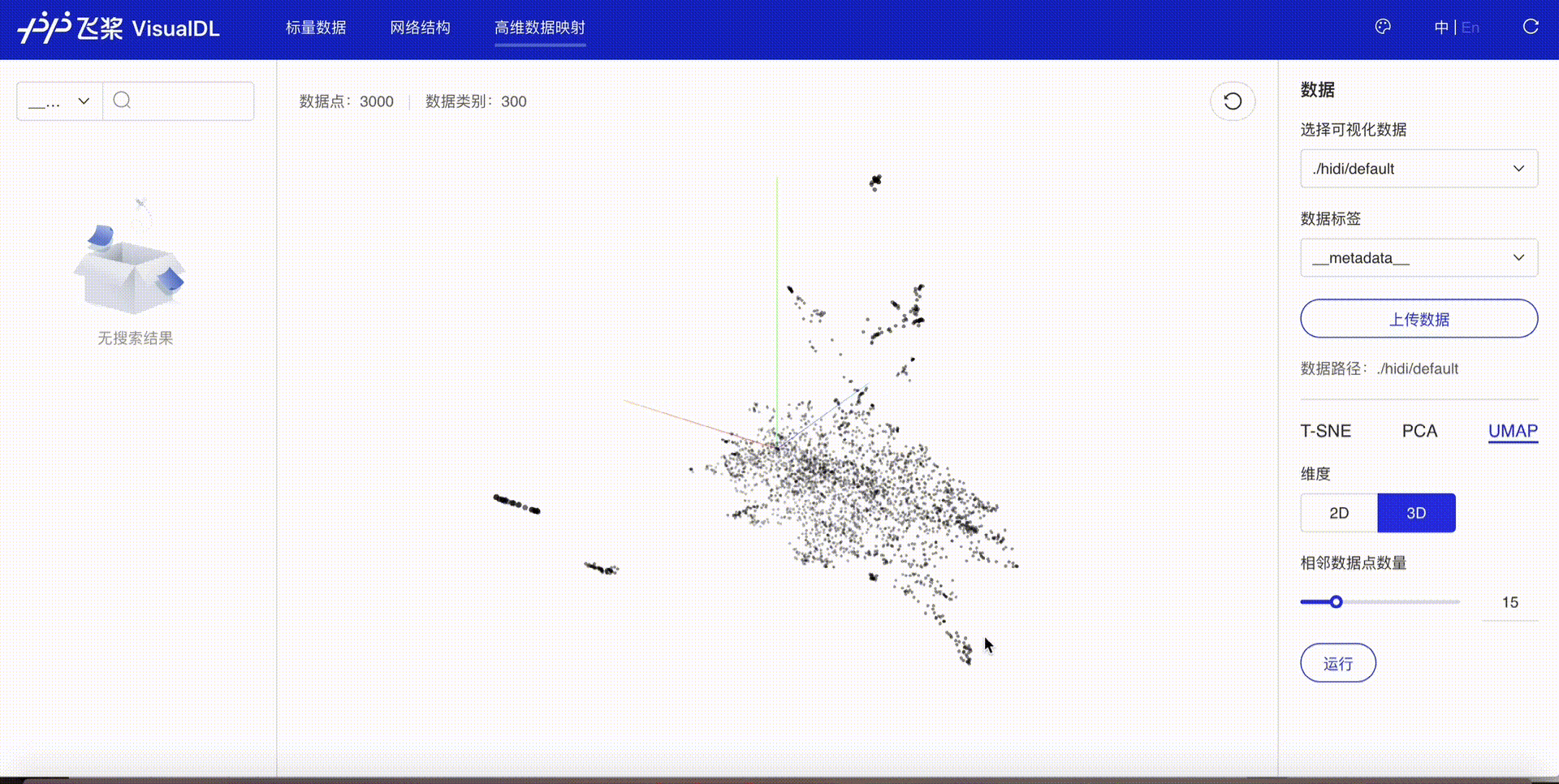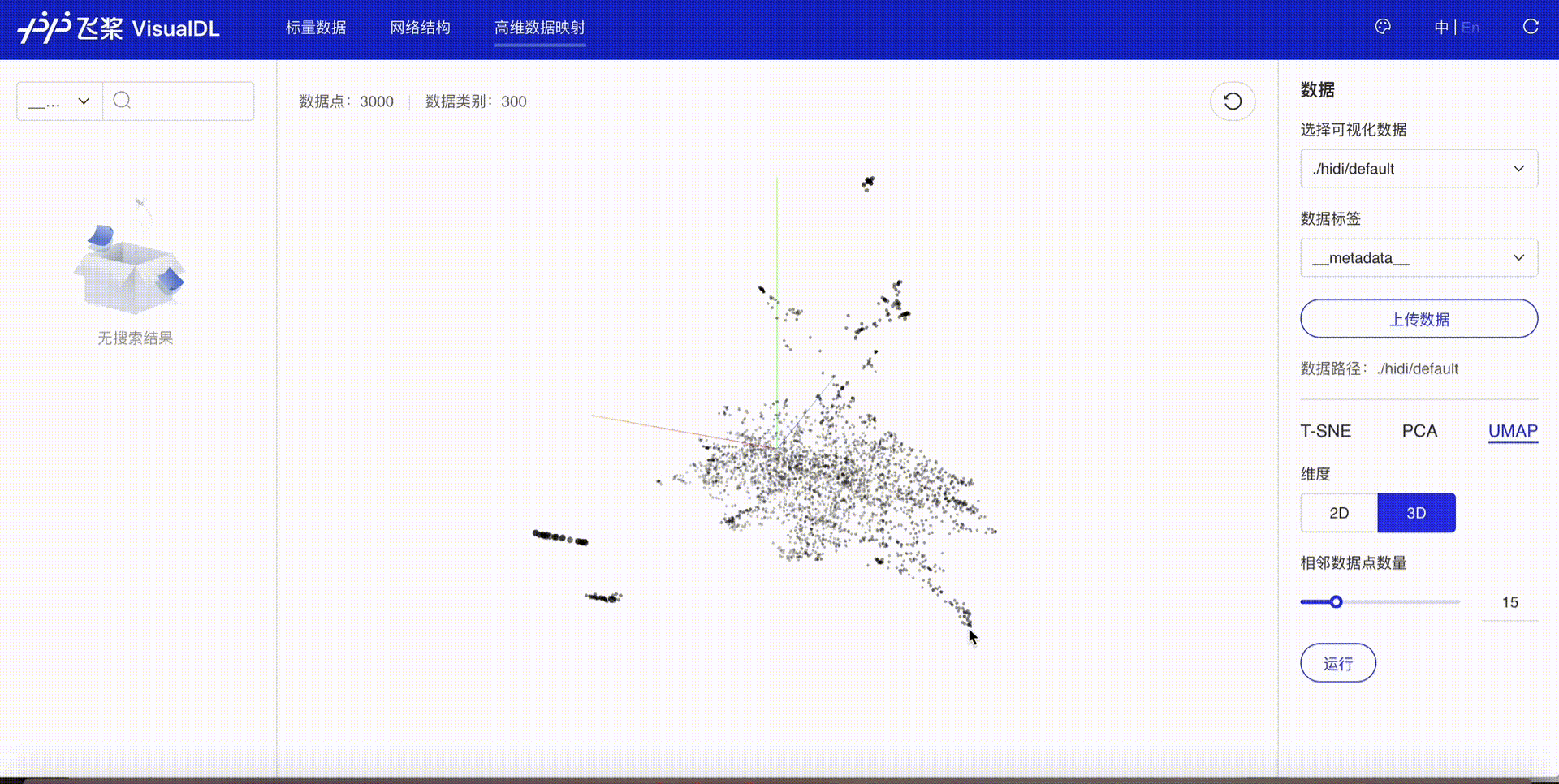
In addition to embedding visualization, VisualDL supports scalar, image and audio visualization, significantly improving training efficiency. For more details, refer to VisualDL Documentation.
Calculating Cosine Similarity of Word Vectors#
score = token_embedding.cosine_sim("China", "United States")
print(score) # 0.49586025
Computing Word Vector Inner Product#
score = token_embedding.dot("China", "United States")
print(score) # 8.611071
Training#
Below is a simple example of using TokenEmbedding for network construction. For more detailed training procedures, please refer to Word Embedding with PaddleNLP.
in_words = paddle.to_tensor([0, 2, 3])
input_embeddings = token_embedding(in_words)
linear = paddle.nn.Linear(token_embedding.embedding_dim, 20)
input_fc = linear(input_embeddings)
print(input_fc)
Tensor(shape=[3, 20], dtype=float32, place=CPUPlace, stop_gradient=False,
[[ 0. , 0. , 0. , ..., 0. , 0. , 0. ],
[-0.23473957, 0.17878169, 0.07215232, ..., 0.03698236, 0.14291850, 0.05136518],
[-0.42466098, 0.15017235, -0.04780108, ..., -0.04995505, 0.15847842, 0.00025209]])
Tokenization#
from paddlenlp.data import JiebaTokenizer
tokenizer = JiebaTokenizer(vocab=token_embedding.vocab)
words = tokenizer.cut("Chinese people")
print(words) # ['中国人', '民']
tokens = tokenizer.encode("Chinese people")
print(tokens) # [12530, 1334]
Pretrained Models#
Below is a list of pretrained embedding models supported by PaddleNLP:
Model naming convention: ${training_model}.${corpus}.${embedding_type}.${dimension} {co-occurrence type}.dim${dimension}
There are three models: Word2Vec (w2v, skip-gram), GloVe (glove), and FastText (fasttext).
Chinese Word Vectors#
The following pretrained word vectors are provided by Chinese-Word-Vectors.
Multiple target word vectors are trained for each corpus based on different types of contexts. The second column onwards represents different context types. Below are the context categories:
Word indicates the context for predicting the target word during training is a single Word.
Word + N-gram indicates the context for predicting the target word during training is a Word or N-gram, where bigram represents 2-grams, and ngram.1-2 represents 1-gram or 2-grams.
Word + Character indicates the context for predicting the target word during training is a Word or Character, where word-character.char1-2 means the context is 1 or 2 Characters.
Word + Character + Ngram indicates the context for predicting the target word during training is a Word, Character, or Ngram. bigram-char means the context is 2-grams or 1 Character.
| Corpus | Word | Word + N-gram | Word + Character | Word + Character + N-gram |
|---|---|---|---|---|
| Baidu Encyclopedia 百度百科 | w2v.baidu_encyclopedia.target.word-word.dim300 | w2v.baidu_encyclopedia.target.word-ngram.1-2.dim300 | w2v.baidu_encyclopedia.target.word-character.char1-2.dim300 | w2v.baidu_encyclopedia.target.bigram-char.dim300 |
| Wikipedia_zh 中文维基百科 | w2v.wiki.target.word-word.dim300 | w2v.wiki.target.word-bigram.dim300 | w2v.wiki.target.word-char.dim300 | w2v.wiki.target.bigram-char.dim300 |
| People's Daily News 人民日报 | w2v.people_daily.target.word-word.dim300 | w2v.people_daily.target.word-bigram.dim300 | w2v.people_daily.target.word-char.dim300 | w2v.people_daily.target.bigram-char.dim300 |
| Sogou News 搜狗新闻 | w2v.sogou.target.word-word.dim300 | w2v.sogou.target.word-bigram.dim300 | w2v.sogou.target.word-char.dim300 | w2v.sogou.target.bigram-char.dim300 |
| Financial News 金融新闻 | w2v.financial.target.word-word.dim300 | w2v.financial.target.word-bigram.dim300 | w2v.financial.target.word-char.dim300 | w2v.financial.target.bigram-char.dim300 |
| Zhihu_QA 知乎问答 | w2v.zhihu.target.word-word.dim300 | w2v.zhihu.target.word-bigram.dim300 | w2v.zhihu.target.word-char.dim300 | w2v.zhihu.target.bigram-char.dim300 |
| Weibo 微博 | w2v.weibo.target.word-word.dim300 | w2v.weibo.target.word-bigram.dim300 | w2v.weibo.target.word-char.dim300 | w2v.weibo.target.bigram-char.dim300 |
| Literature 文学作品 | w2v.literature.target.word-word.dim300 | w2v.literature.target.word-bigram.dim300 | w2v.literature.target.word-char.dim300 | w2v.literature.target.bigram-char.dim300 |
| Complete Library in Four Sections 四库全书 | w2v.sikuquanshu.target.word-word.dim300 | w2v.sikuquanshu.target.word-bigram.dim300 | N/A | N/A |
| Mixed-large 综合 | w2v.mixed-large.target.word-word.dim300 | N/A | w2v.mixed-large.target.word-word.dim300 | N/A |
Specifically, for the Baidu Encyclopedia corpus, separate target and context vectors are provided under different Co-occurrence types:
| Co-occurrence Type | Target Word Vector | Context Word Vector |
|---|---|---|
| Word → Word | w2v.baidu_encyclopedia.target.word-word.dim300 | w2v.baidu_encyclopedia.context.word-word.dim300 |
| Word → Ngram (1-2) | w2v.baidu_encyclopedia.target.word-ngram.1-2.dim300 | w2v.baidu_encyclopedia.context.word-ngram.1-2.dim300 |
| Word → Ngram (1-3) | w2v.baidu_encyclopedia.target.word-ngram.1-3.dim300 | w2v.baidu_encyclopedia.context.word-ngram.1-3.dim300 |
| Ngram (1-2) → Ngram (1-2) | w2v.baidu_encyclopedia.target.word-ngram.2-2.dim300 | w2v.baidu_encyclopedia.target.word-ngram.2-2.dim300 |
| Word → Character (1) | w2v.baidu_encyclopedia.target.word-character.char1-1.dim300 | w2v.baidu_encyclopedia.context.word-character.char1-1.dim300 |
| Word → Character (1-2) | w2v.baidu_encyclopedia.target.word-character.char1-2.dim300 | w2v.baidu_encyclopedia.context.word-character.char1-2.dim300 |
| Word → Character (1-4) | w2v.baidu_encyclopedia.target.word-character.char1-4.dim300 | w2v.baidu_encyclopedia.context.word-character.char1-4.dim300 |
| Word → Word (left/right) | w2v.baidu_encyclopedia.target.word-wordLR.dim300 | w2v.baidu_encyclopedia.context.word-wordLR.dim300 |
| Word → Word (distance) | w2v.baidu_encyclopedia.target.word-wordPosition.dim300 | w2v.baidu_encyclopedia.context.word-wordPosition.dim300 |
English Word Vectors#
Word2Vec#
| Corpus | Name |
|---|---|
| Google News | w2v.google_news.target.word-word.dim300.en |
GloVe#
| Corpus | 25d | 50d | 100d | 200d | 300d |
|---|---|---|---|---|---|
| Wiki2014 + GigaWord | N/A | glove.wiki2014-gigaword.target.word-word.dim50.en | glove.wiki2014-gigaword.target.word-word.dim100.en | glove.wiki2014-gigaword.target.word-word.dim200.en | glove.wiki2014-gigaword.target.word-word.dim300.en |
| glove.twitter.target.word-word.dim25.en | glove.twitter.target.word-word.dim50.en | glove.twitter.target.word-word.dim100.en | glove.twitter.target.word-word.dim200.en | N/A |
FastText#
| Corpus | Name |
|---|---|
| Wiki2017 | fasttext.wiki-news.target.word-word.dim300.en |
| Crawl | fasttext.crawl.target.word-word.dim300.en |
Usage#
The model names mentioned above can be directly used as parameters.
padddlenlp.embeddings.TokenEmbedding, which loads the corresponding model. For example, to load the pre-trained model trained via FastText on Wiki2017 corpus (fasttext.wiki-news.target.word-word.dim300.en), simply execute the following code:
import paddle
from paddlenlp.embeddings import TokenEmbedding
token_embedding = TokenEmbedding(embedding_name="fasttext.wiki-news.target.word-word.dim300.en")
Model Information#
| Model | File Size | Vocabulary Size |
|---|---|---|
| w2v.baidu_encyclopedia.target.word-word.dim300 | 678.21 MB | 635965 |
| w2v.baidu_encyclopedia.target.word-character.char1-1.dim300 | 679.15 MB | 636038 |
| w2v.baidu_encyclopedia.target.word-character.char1-2.dim300 | 679.30 MB | 636038 |
| w2v.baidu_encyclopedia.target.word-character.char1-4.dim300 | 679.51 MB | 636038 |
| w2v.baidu_encyclopedia.target.word-ngram.1-2.dim300 | 679.48 MB | 635977 |
| w2v.baidu_encyclopedia.target.word-ngram.1-3.dim300 | 671.27 MB | 628669 |
| w2v.baidu_encyclopedia.target.word-ngram.2-2.dim300 | 7.28 GB | 6969069 |
| w2v.baidu_encyclopedia.target.word-wordLR.dim300 | 678.22 MB | 635958 |
| w2v.baidu_encyclopedia.target.word-wordPosition.dim300 | 679.32 MB | 636038 |
| w2v.baidu_encyclopedia.target.bigram-char.dim300 | 679.29 MB | 635976 |
| w2v.baidu_encyclopedia.context.word-word.dim300 | 677.74 MB | 635952 |
| w2v.baidu_encyclopedia.context.word-character.char1-1.dim300 | 678.65 MB | 636200 |
| w2v.baidu_encyclopedia.context.word-character.char1-2.dim300 | 844.23 MB | 792631 |
| w2v.baidu_encyclopedia.context.word-character.char1-4.dim300 | 1.16 GB | 1117461 |
| w2v.baidu_encyclopedia.context.word-ngram.1-2.dim300 | 7.25 GB | 6967598 |
| w2v.baidu_encyclopedia.context.word-ngram.1-3.dim300 | 5.21 GB | 5000001 |
| w2v.baidu_encyclopedia.context.word-ngram.2-2.dim300 | 7.26 GB | 6968998 |
| w2v.baidu_encyclopedia.context.word-wordLR.dim300 | 1.32 GB | 1271031 |
| w2v.baidu_encyclopedia.context.word-wordPosition.dim300 | 6.47 GB | 6293920 |
| w2v.wiki.target.bigram-char.dim300 | 375.98 MB | 352274 |
| w2v.wiki.target.word-char.dim300 | 375.52 MB | 352223 |
| w2v.wiki.target.word-word.dim300 | 374.95 MB | 352219 |
| w2v.wiki.target.word-bigram.dim300 | 375.72 MB | 352219 |
| w2v.people_daily.target.bigram-char.dim300 | 379.96 MB | 356055 |
| w2v.people_daily.target.word-char.dim300 | 379.45 MB | 355998 |
| w2v.people_daily.target.word-word.dim300 | 378.93 MB | 355989 |
| w2v.people_daily.target.word-bigram.dim300 | 379.68 MB | 355991 |
| w2v.weibo.target.bigram-char.dim300 | 208.24 MB | 195199 |
| w2v.weibo.target.word-char.dim300 | 208.03 MB | 195204 |
| w2v.weibo.target.word-word.dim300 | 207.94 MB | 195204 |
| w2v.weibo.target.word-bigram.dim300 | 208.19 MB | 195204 |
| w2v.sogou.target.bigram-char.dim300 | 389.81 MB | 365112 |
| w2v.sogou.target.word-char.dim300 | 389.89 MB | 365078 |
| w2v.sogou.target.word-word.dim300 | 388.66 MB | 364992 |
| w2v.sogou.target.word-bigram.dim300 | 388.66 MB | 364994 |
| w2v.zhihu.target.bigram-char.dim300 | 277.35 MB | 259755 |
| w2v.zhihu.target.word-char.dim300 | 277.40 MB | 259940 |
| w2v.zhihu.target.word-word.dim300 | 276.98 MB | 259871 |
| w2v.zhihu.target.word-bigram.dim300 | 277.53 MB | 259885 |
| w2v.financial.target.bigram-char.dim300 | 499.52 MB | 467163 |
| w2v.financial.target.word-char.dim300 | 499.17 MB | 467343 |
| w2v.financial.target.word-word.dim300 | 498.94 MB | 467324 |
| w2v.financial.target.word-bigram.dim300 | 499.54 MB | 467331 |
| w2v.literature.target.bigram-char.dim300 | 200.69 MB | 187975 |
| w2v.literature.target.word-char.dim300 | 200.44 MB | 187980 |
| w2v.literature.target.word-word.dim300 | 200.28 MB | 187961 |
| w2v.literature.target.word-bigram.dim300 | 200.59 MB | 187962 |
| w2v.sikuquanshu.target.word-word.dim300 | 20.70 MB | 19529 |
| w2v.sikuquanshu.target.word-bigram.dim300 | 20.77 MB | 19529 |
| w2v.mixed-large.target.word-char.dim300 | 1.35 GB | 1292552 |
| w2v.mixed-large.target.word-word.dim300 | 1.35 GB | 1292483 |
| w2v.google_news.target.word-word.dim300.en | 1.61 GB | 3000000 |
| glove.wiki2014-gigaword.target.word-word.dim50.en | 73.45 MB | 400002 |
| glove.wiki2014-gigaword.target.word-word.dim100.en | 143.30 MB | 400002 |
| glove.wiki2014-gigaword.target.word-word.dim200.en | 282.97 MB | 400002 |
| glove.wiki2014-gigaword.target.word-word.dim300.en | 422.83 MB | 400002 |
| glove.twitter.target.word-word.dim25.en | 116.92 MB | 1193516 |
| glove.twitter.target.word-word.dim50.en | 221.64 MB | 1193516 |
| glove.twitter.target.word-word.dim100.en | 431.08 MB | 1193516 |
| glove.twitter.target.word-word.dim200.en | 848.56 MB | 1193516 |
| fasttext.wiki-news.target.word-word.dim300.en | 541.63 MB | 999996 |
| fasttext.crawl.target.word-word.dim300.en | 1.19 GB | 2000002 |
Acknowledgments#
Thanks to Chinese-Word-Vectors for providing Chinese pretrained Word2Vec embeddings.
Thanks to GloVe Project for providing English GloVe embeddings.
Thanks to FastText Project for providing English pretrained embeddings.
Reference Papers#
Li, Shen, et al. “Analogical reasoning on chinese morphological and semantic relations.” arXiv preprint arXiv:1805.06504 (2018).
Qiu, Yuanyuan, et al. “Revisiting correlations between intrinsic and extrinsic evaluations of word embeddings.” Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data. Springer, Cham, 2018. 209-221.
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation.
T. Mikolov, E. Grave, P. Bojanowski, C. Puhrsch, A. Joulin. Advances in Pre-Training Distributed Word Representations.